 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Distributed Dual Coordinate Optimization Framework for Regularized Loss Minimization
Paper and Code
Aug 25, 2017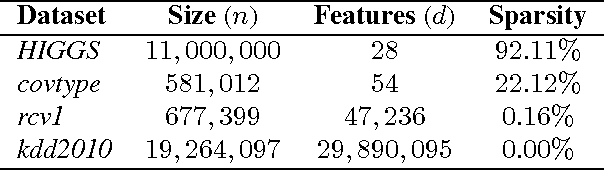
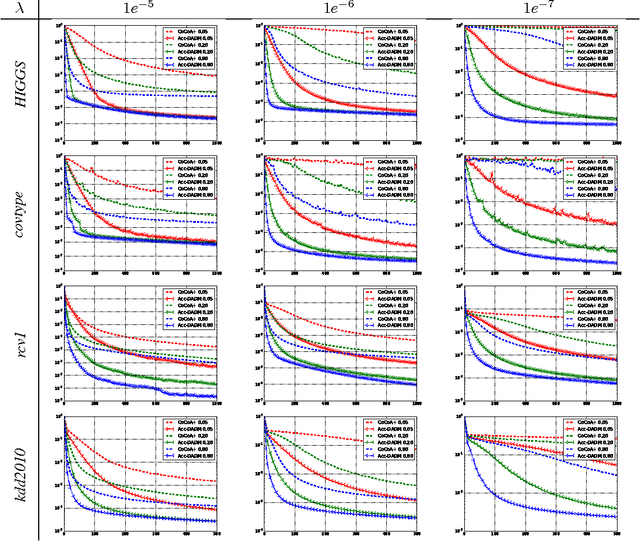
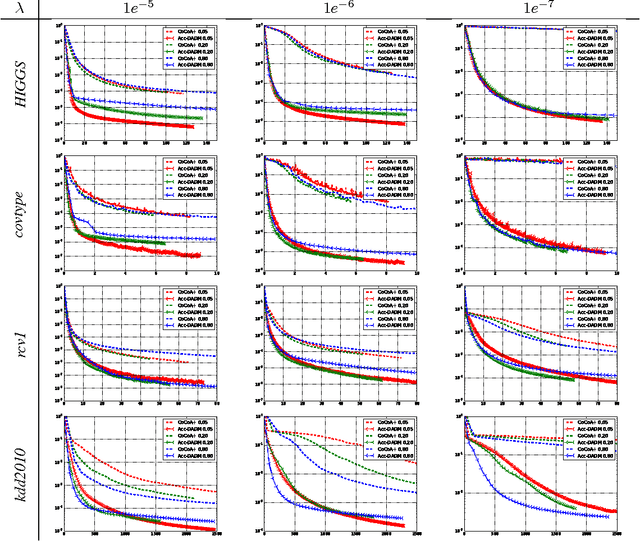

In modern large-scale machine learning applications, the training data are often partitioned and stored on multiple machines. It is customary to employ the "data parallelism" approach, where the aggregated training loss is minimized without moving data across machines. In this paper, we introduce a novel distributed dual formulation for regularized loss minimization problems that can directly handle data parallelism in the distributed setting. This formulation allows us to systematically derive dual coordinate optimization procedures, which we refer to as Distributed Alternating Dual Maximization (DADM). The framework extends earlier studies described in (Boyd et al., 2011; Ma et al., 2015a; Jaggi et al., 2014; Yang, 2013) and has rigorous theoretical analyses. Moreover with the help of the new formulation, we develop the accelerated version of DADM (Acc-DADM) by generalizing the acceleration technique from (Shalev-Shwartz and Zhang, 2014) to the distributed setting. We also provide theoretical results for the proposed accelerated version and the new result improves previous ones (Yang, 2013; Ma et al., 2015a) whose runtimes grow linearly on the condition number. Our empirical studies validate our theory and show that our accelerated approach significantly improves the previous state-of-the-art distributed dual coordinate optimization algorithms.