 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Combination for Short Utterance Speaker Recognition
Paper and Code
Sep 27, 2016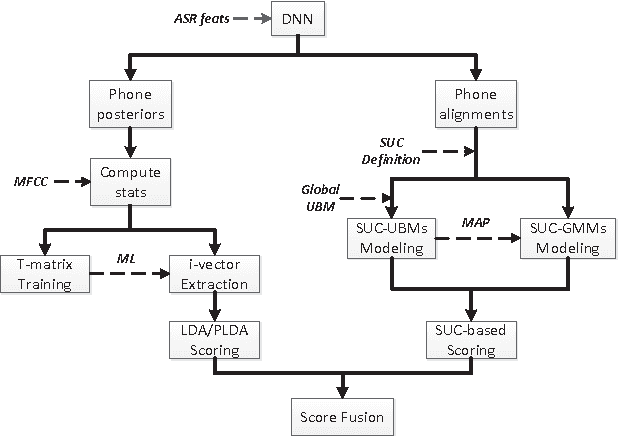
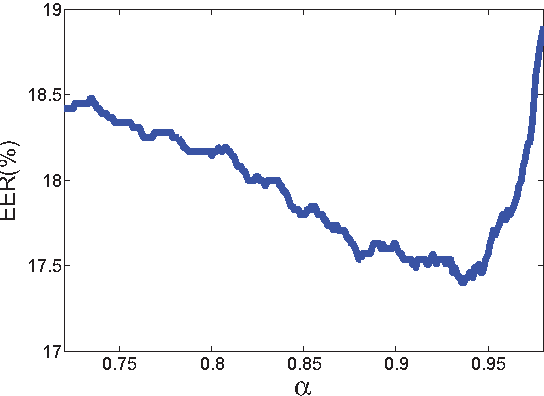

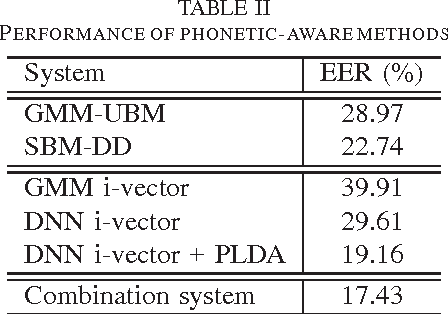
For text-independent short-utterance speaker recognition (SUSR), the performance often degrades dramatically. This paper presents a combination approach to the SUSR tasks with two phonetic-aware systems: one is the DNN-based i-vector system and the other is our recently proposed subregion-based GMM-UBM system. The former employs phone posteriors to construct an i-vector model in which the shared statistics offers stronger robustness against limited test data, while the latter establishes a phone-dependent GMM-UBM system which represents speaker characteristics with more details. A score-level fusion is implemented to integrate the respective advantages from the two systems. Experimental results show that for the text-independent SUSR task, both the DNN-based i-vector system and the subregion-based GMM-UBM system outperform their respective baselines, and the score-level system combination delivers performance improvement.