 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning values across many orders of magnitude
Paper and Code
Aug 16, 2016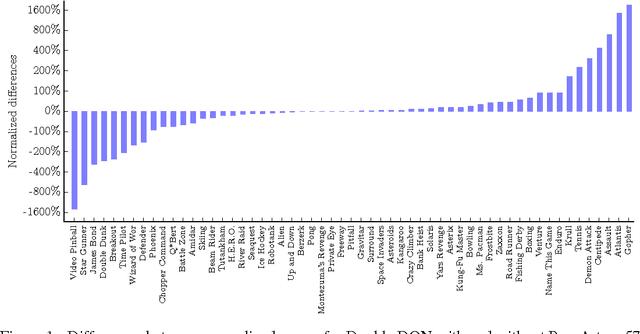
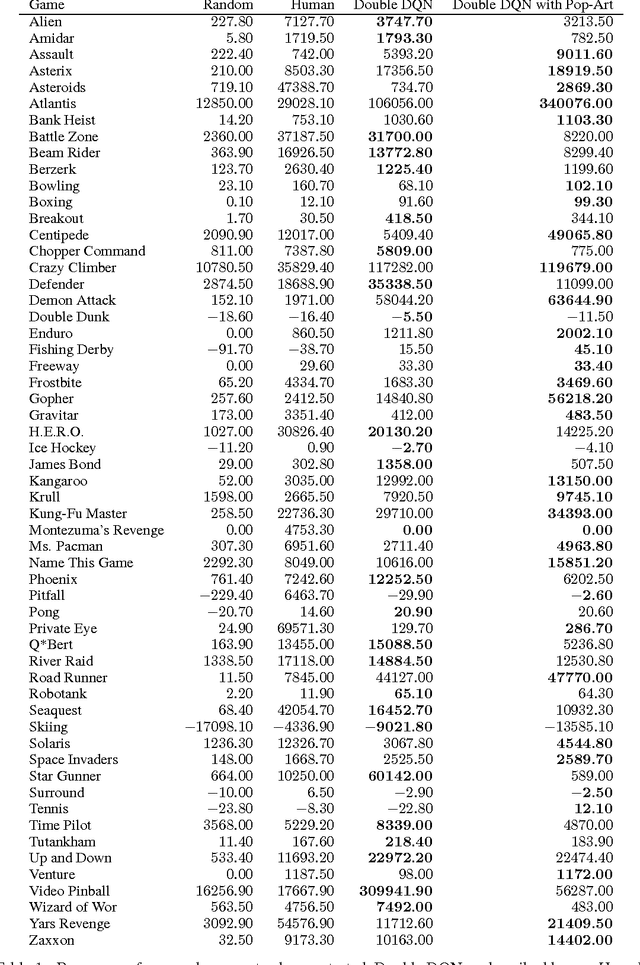
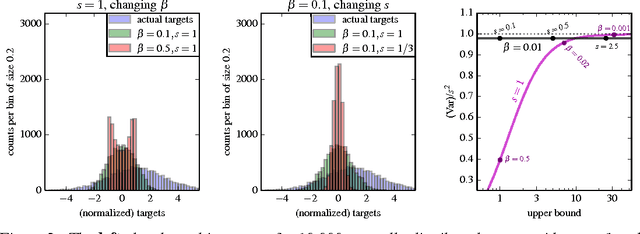
Most learning algorithms are not invariant to the scale of the function that is being approximated. We propose to adaptively normalize the targets used in learning. This is useful in value-based reinforcement learning, where the magnitude of appropriate value approximations can change over time when we update the policy of behavior. Our main motivation is prior work on learning to play Atari games, where the rewards were all clipped to a predetermined range. This clipping facilitates learning across many different games with a single learning algorithm, but a clipped reward function can result in qualitatively different behavior. Using the adaptive normalization we can remove this domain-specific heuristic without diminishing overall performance.