 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Structured Probability Matrices
Paper and Code
Feb 06, 2018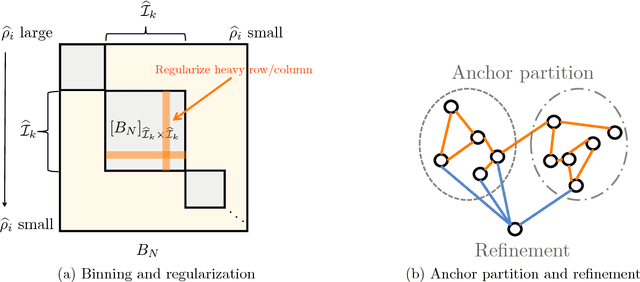
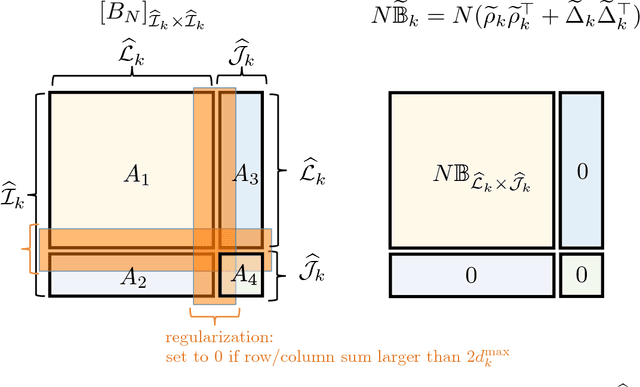
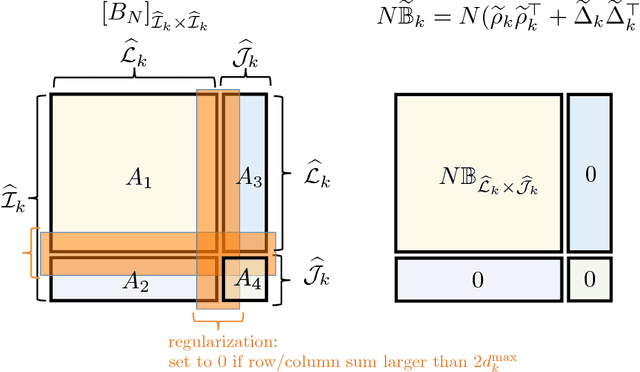
We consider the problem of accurately recovering a matrix B of size M by M , which represents a probability distribution over M2 outcomes, given access to an observed matrix of "counts" generated by taking independent samples from the distribution B. How can structural properties of the underlying matrix B be leveraged to yield computationally efficient and information theoretically optimal reconstruction algorithms? When can accurate reconstruction be accomplished in the sparse data regime? This basic problem lies at the core of a number of questions that are currently being considered by different communities, including building recommendation systems and collaborative filtering in the sparse data regime, community detection in sparse random graphs, learning structured models such as topic models or hidden Markov models, and the efforts from the natural language processing community to compute "word embeddings". Our results apply to the setting where B has a low rank structure. For this setting, we propose an efficient algorithm that accurately recovers the underlying M by M matrix using Theta(M) samples. This result easily translates to Theta(M) sample algorithms for learning topic models and learning hidden Markov Models. These linear sample complexities are optimal, up to constant factors, in an extremely strong sense: even testing basic properties of the underlying matrix (such as whether it has rank 1 or 2) requires Omega(M) samples. We provide an even stronger lower bound where distinguishing whether a sequence of observations were drawn from the uniform distribution over M observations versus being generated by an HMM with two hidden states requires Omega(M) observations. This precludes sublinear-sample hypothesis tests for basic properties, such as identity or uniformity, as well as sublinear sample estimators for quantities such as the entropy rate of HMMs.