 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally-Supervised Deep Hybrid Model for Scene Recognition
Paper and Code
Dec 15, 2016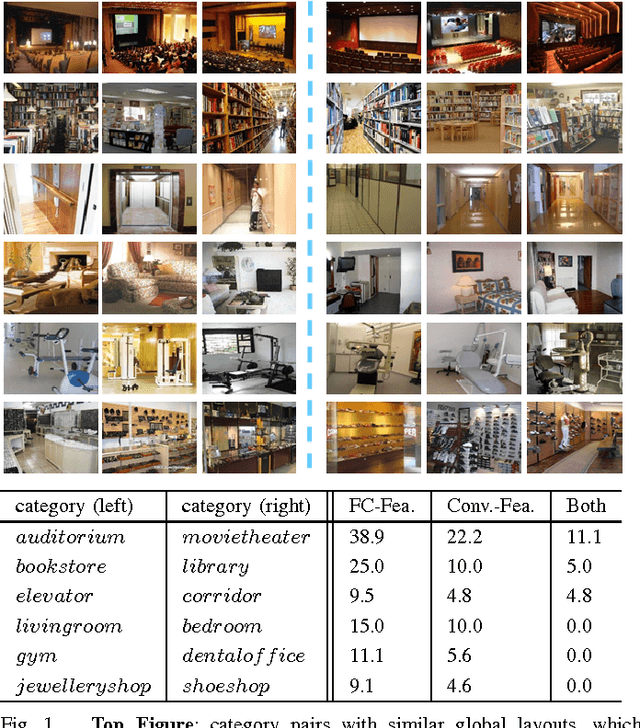
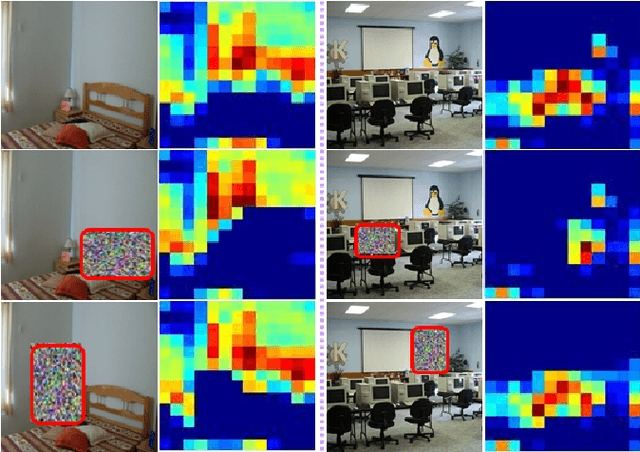

Convolutional neural networks (CNN) have recently achieved remarkable successes in various image classification and understanding tasks. The deep features obtained at the top fully-connected layer of the CNN (FC-features) exhibit rich global semantic information and are extremely effective in image classification. On the other hand, the convolutional features in the middle layers of the CNN also contain meaningful local information, but are not fully explored for image representation. In this paper, we propose a novel Locally-Supervised Deep Hybrid Model (LS-DHM) that effectively enhances and explores the convolutional features for scene recognition. Firstly, we notice that the convolutional features capture local objects and fine structures of scene images, which yield important cues for discriminating ambiguous scenes, whereas these features are significantly eliminated in the highly-compressed FC representation. Secondly, we propose a new Local Convolutional Supervision (LCS) layer to enhance the local structure of the image by directly propagating the label information to the convolutional layers. Thirdly, we propose an efficient Fisher Convolutional Vector (FCV) that successfully rescues the orderless mid-level semantic information (e.g. objects and textures) of scene image. The FCV encodes the large-sized convolutional maps into a fixed-length mid-level representation, and is demonstrated to be strongly complementary to the high-level FC-features. Finally, both the FCV and FC-features are collaboratively employed in the LSDHM representation, which achieves outstanding performance in our experiments. It obtains 83.75% and 67.56% accuracies respectively on the heavily benchmarked MIT Indoor67 and SUN397 datasets, advancing the stat-of-the-art substantially.