 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Restricted Visual Turing Test for Deep Scene and Event Understanding
Paper and Code
Dec 16, 2015
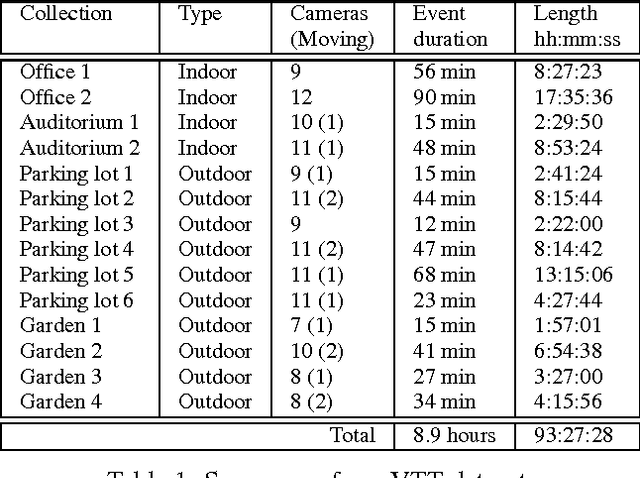
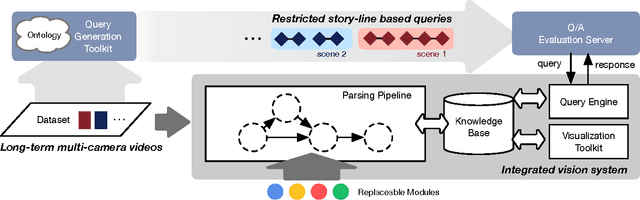
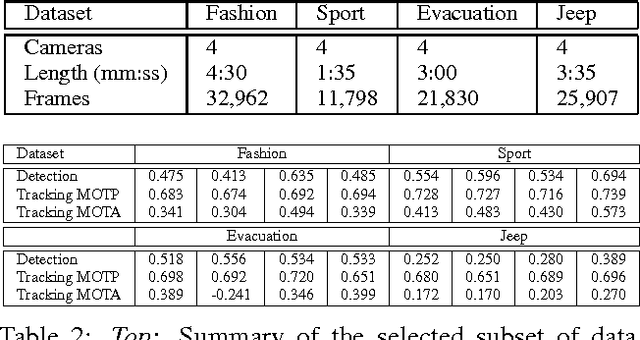
This paper presents a restricted visual Turing test (VTT) for story-line based deep understanding in long-term and multi-camera captured videos. Given a set of videos of a scene (such as a multi-room office, a garden, and a parking lot.) and a sequence of story-line based queries, the task is to provide answers either simply in binary form "true/false" (to a polar query) or in an accurate natural language description (to a non-polar query). Queries, polar or non-polar, consist of view-based queries which can be answered from a particular camera view and scene-centered queries which involves joint inference across different cameras. The story lines are collected to cover spatial, temporal and causal understanding of input videos. The data and queries distinguish our VTT from recently proposed visual question answering in images and video captioning. A vision system is proposed to perform joint video and query parsing which integrates different vision modules, a knowledge base and a query engine. The system provides unified interfaces for different modules so that individual modules can be reconfigured to test a new method. We provide a benchmark dataset and a toolkit for ontology guided story-line query generation which consists of about 93.5 hours videos captured in four different locations and 3,426 queries split into 127 story lines. We also provide a baseline implementation and result analyses.