 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle performance for visual captioning
Paper and Code
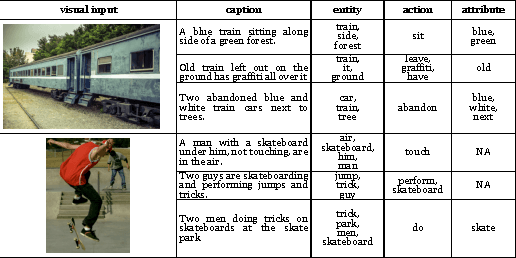
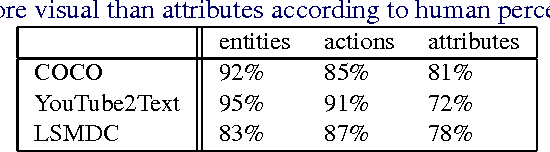
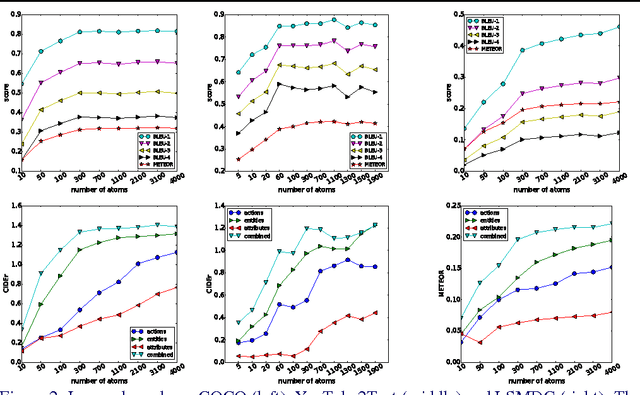
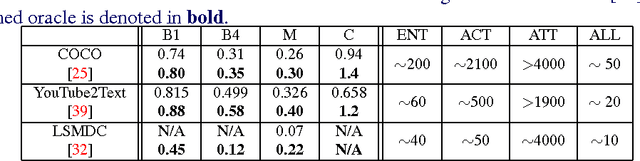
The task of associating images and videos with a natural language description has attracted a great amount of attention recently. Rapid progress has been made in terms of both developing novel algorithms and releasing new datasets. Indeed, the state-of-the-art results on some of the standard datasets have been pushed into the regime where it has become more and more difficult to make significant improvements. Instead of proposing new models, this work investigates the possibility of empirically establishing performance upper bounds on various visual captioning datasets without extra data labelling effort or human evaluation. In particular, it is assumed that visual captioning is decomposed into two steps: from visual inputs to visual concepts, and from visual concepts to natural language descriptions. One would be able to obtain an upper bound when assuming the first step is perfect and only requiring training a conditional language model for the second step. We demonstrate the construction of such bounds on MS-COCO, YouTube2Text and LSMDC (a combination of M-VAD and MPII-MD). Surprisingly, despite of the imperfect process we used for visual concept extraction in the first step and the simplicity of the language model for the second step, we show that current state-of-the-art models fall short when being compared with the learned upper bounds. Furthermore, with such a bound, we quantify several important factors concerning image and video captioning: the number of visual concepts captured by different models, the trade-off between the amount of visual elements captured and their accuracy, and the intrinsic difficulty and blessing of different datasets.