 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Pooling Functions in Convolutional Neural Networks: Mixed, Gated, and Tree
Paper and Code
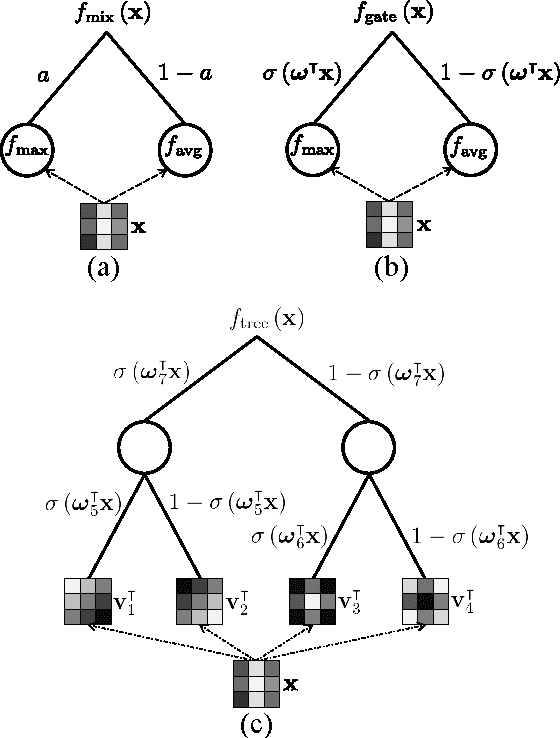
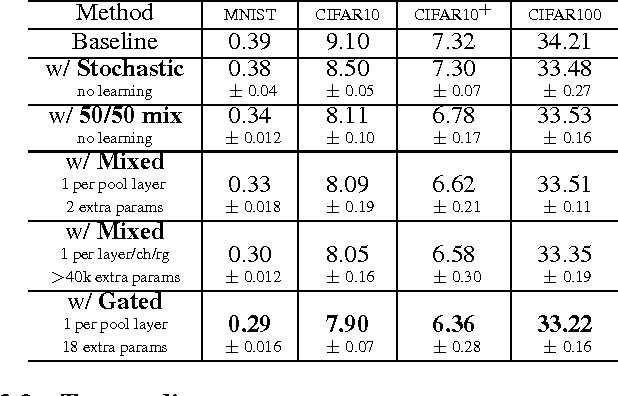
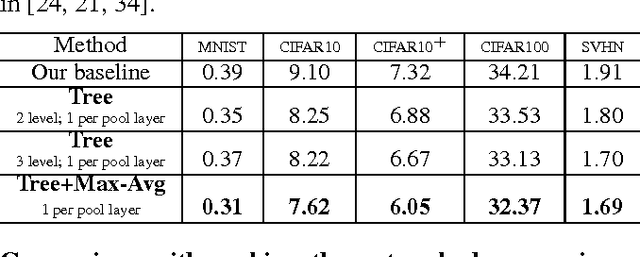
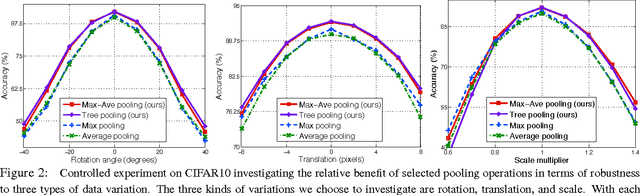
We seek to improve deep neural networks by generalizing the pooling operations that play a central role in current architectures. We pursue a careful exploration of approaches to allow pooling to learn and to adapt to complex and variable patterns. The two primary directions lie in (1) learning a pooling function via (two strategies of) combining of max and average pooling, and (2) learning a pooling function in the form of a tree-structured fusion of pooling filters that are themselves learned. In our experiments every generalized pooling operation we explore improves performance when used in place of average or max pooling. We experimentally demonstrate that the proposed pooling operations provide a boost in invariance properties relative to conventional pooling and set the state of the art on several widely adopted benchmark datasets; they are also easy to implement, and can be applied within various deep neural network architectures. These benefits come with only a light increase in computational overhead during training and a very modest increase in the number of model parameters.