 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Happened to My Dog in That Network: Unraveling Top-down Generators in Convolutional Neural Networks
Nov 23, 2015

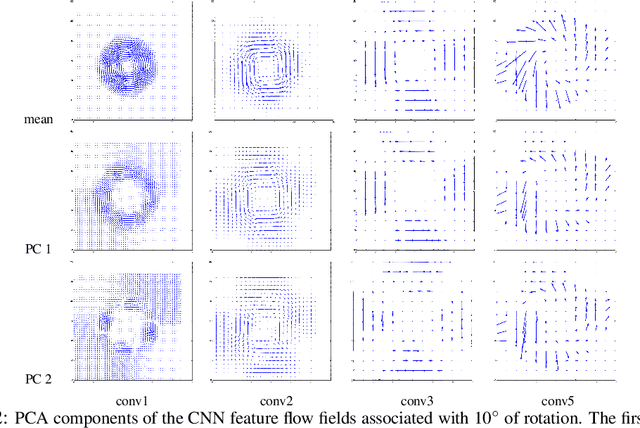

Top-down information plays a central role in human perception, but plays relatively little role in many current state-of-the-art deep networks, such as Convolutional Neural Networks (CNNs). This work seeks to explore a path by which top-down information can have a direct impact within current deep networks. We explore this path by learning and using "generators" corresponding to the network internal effects of three types of transformation (each a restriction of a general affine transformation): rotation, scaling, and translation. We demonstrate how these learned generators can be used to transfer top-down information to novel settings, as mediated by the "feature flows" that the transformations (and the associated generators) correspond to inside the network. Specifically, we explore three aspects: 1) using generators as part of a method for synthesizing transformed images --- given a previously unseen image, produce versions of that image corresponding to one or more specified transformations, 2) "zero-shot learning" --- when provided with a feature flow corresponding to the effect of a transformation of unknown amount, leverage learned generators as part of a method by which to perform an accurate categorization of the amount of transformation, even for amounts never observed during training, and 3) (inside-CNN) "data augmentation" --- improve the classification performance of an existing network by using the learned generators to directly provide additional training "inside the CNN".
Generalizing Pooling Functions in Convolutional Neural Networks: Mixed, Gated, and Tree
Oct 10, 2015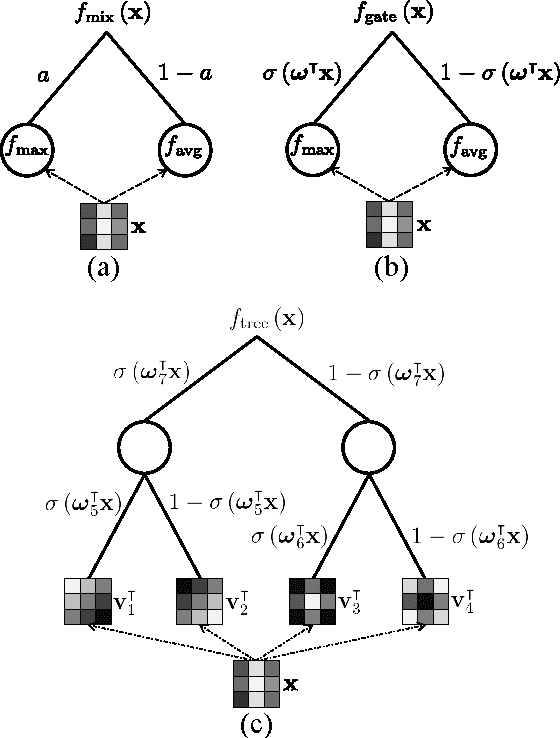
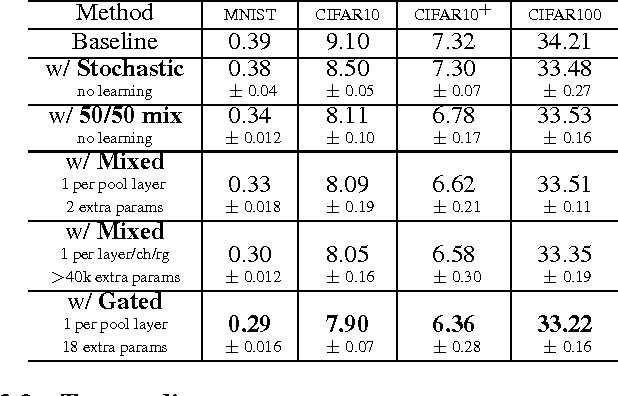
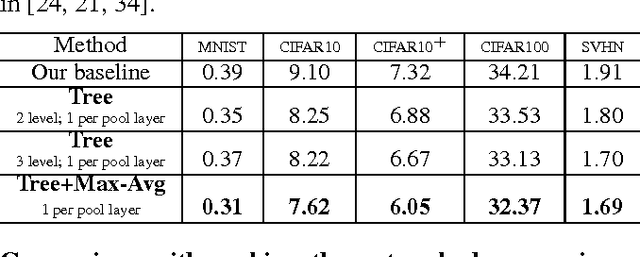
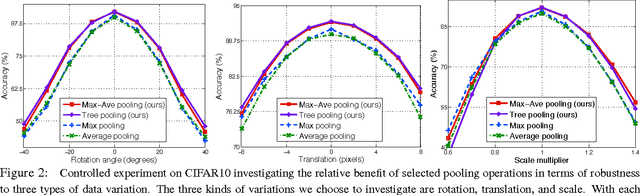
We seek to improve deep neural networks by generalizing the pooling operations that play a central role in current architectures. We pursue a careful exploration of approaches to allow pooling to learn and to adapt to complex and variable patterns. The two primary directions lie in (1) learning a pooling function via (two strategies of) combining of max and average pooling, and (2) learning a pooling function in the form of a tree-structured fusion of pooling filters that are themselves learned. In our experiments every generalized pooling operation we explore improves performance when used in place of average or max pooling. We experimentally demonstrate that the proposed pooling operations provide a boost in invariance properties relative to conventional pooling and set the state of the art on several widely adopted benchmark datasets; they are also easy to implement, and can be applied within various deep neural network architectures. These benefits come with only a light increase in computational overhead during training and a very modest increase in the number of model parameters.