 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporal Alignment Uncertainty for Efficient Event Detection
Paper and Code
Sep 04, 2015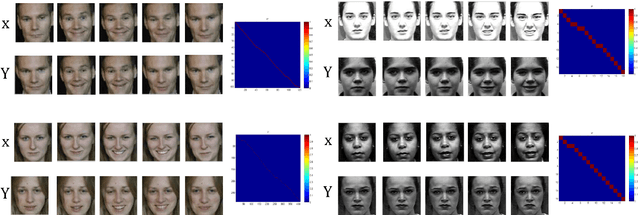

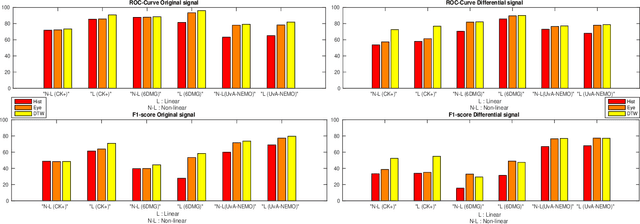
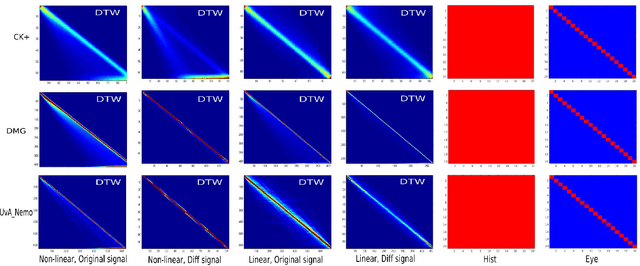
In this paper we tackle the problem of efficient video event detection. We argue that linear detection functions should be preferred in this regard due to their scalability and efficiency during estimation and evaluation. A popular approach in this regard is to represent a sequence using a bag of words (BOW) representation due to its: (i) fixed dimensionality irrespective of the sequence length, and (ii) its ability to compactly model the statistics in the sequence. A drawback to the BOW representation, however, is the intrinsic destruction of the temporal ordering information. In this paper we propose a new representation that leverages the uncertainty in relative temporal alignments between pairs of sequences while not destroying temporal ordering. Our representation, like BOW, is of a fixed dimensionality making it easily integrated with a linear detection function. Extensive experiments on CK+, 6DMG, and UvA-NEMO databases show significant performance improvements across both isolated and continuous event detection tasks.