 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition by Hierarchical Mid-level Action Elements
Paper and Code
Aug 31, 2015
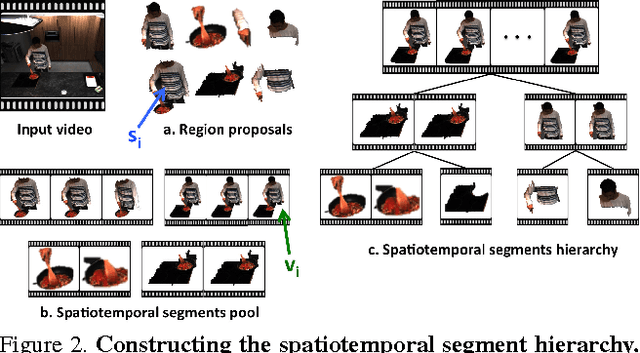
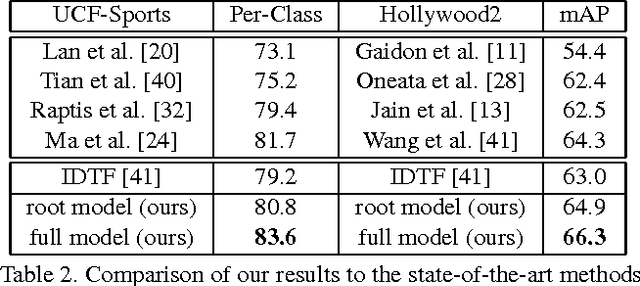
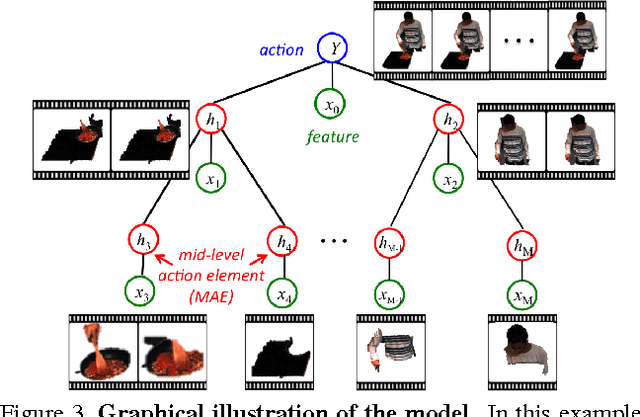
Realistic videos of human actions exhibit rich spatiotemporal structures at multiple levels of granularity: an action can always be decomposed into multiple finer-grained elements in both space and time. To capture this intuition, we propose to represent videos by a hierarchy of mid-level action elements (MAEs), where each MAE corresponds to an action-related spatiotemporal segment in the video. We introduce an unsupervised method to generate this representation from videos. Our method is capable of distinguishing action-related segments from background segments and representing actions at multiple spatiotemporal resolutions. Given a set of spatiotemporal segments generated from the training data, we introduce a discriminative clustering algorithm that automatically discovers MAEs at multiple levels of granularity. We develop structured models that capture a rich set of spatial, temporal and hierarchical relations among the segments, where the action label and multiple levels of MAE labels are jointly inferred. The proposed model achieves state-of-the-art performance in multiple action recognition benchmarks. Moreover, we demonstrate the effectiveness of our model in real-world applications such as action recognition in large-scale untrimmed videos and action parsing.