Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthCam3D: Semantic Understanding With Synthetic Indoor Scenes
Paper and Code
May 01, 2015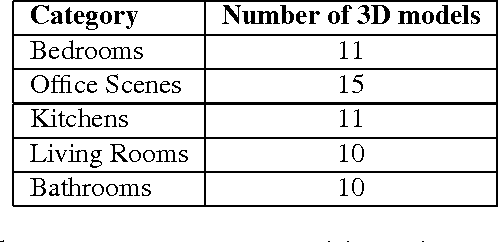



We are interested in automatic scene understanding from geometric cues. To this end, we aim to bring semantic segmentation in the loop of real-time reconstruction. Our semantic segmentation is built on a deep autoencoder stack trained exclusively on synthetic depth data generated from our novel 3D scene library, SynthCam3D. Importantly, our network is able to segment real world scenes without any noise modelling. We present encouraging preliminary results.
View paper on