 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Monolingual Corpora in Neural Machine Translation
Paper and Code
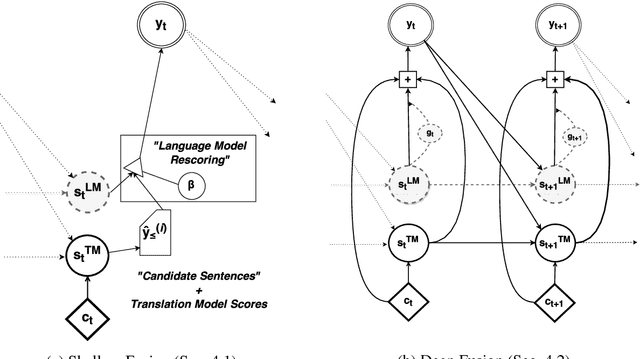

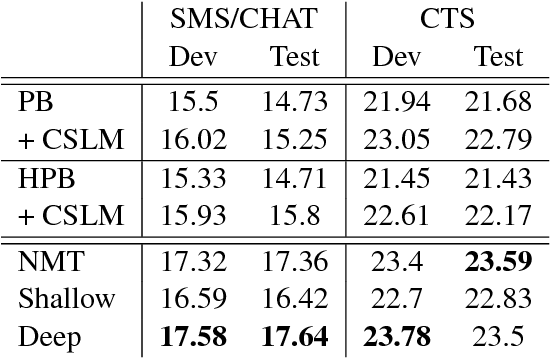
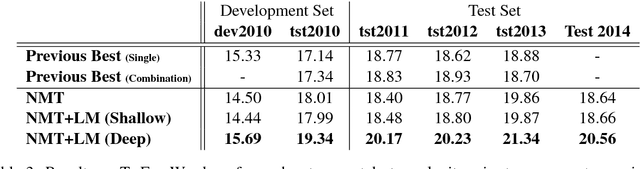
Recent work on end-to-end neural network-based architectures for machine translation has shown promising results for En-Fr and En-De translation. Arguably, one of the major factors behind this success has been the availability of high quality parallel corpora. In this work, we investigate how to leverage abundant monolingual corpora for neural machine translation. Compared to a phrase-based and hierarchical baseline, we obtain up to $1.96$ BLEU improvement on the low-resource language pair Turkish-English, and $1.59$ BLEU on the focused domain task of Chinese-English chat messages. While our method was initially targeted toward such tasks with less parallel data, we show that it also extends to high resource languages such as Cs-En and De-En where we obtain an improvement of $0.39$ and $0.47$ BLEU scores over the neural machine translation baselines, respectively.