Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical modality tagging from rule-based annotations and crowdsourcing
Paper and Code
Mar 04, 2015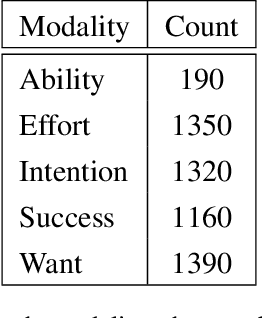
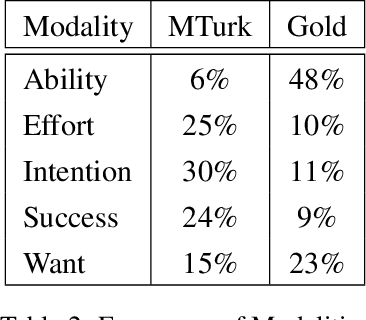
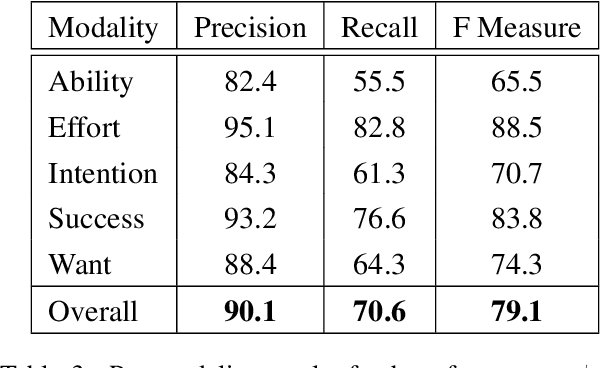
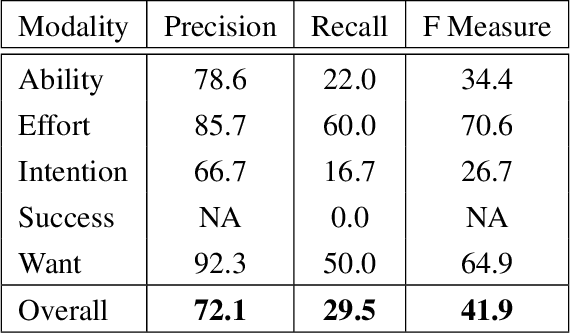
We explore training an automatic modality tagger. Modality is the attitude that a speaker might have toward an event or state. One of the main hurdles for training a linguistic tagger is gathering training data. This is particularly problematic for training a tagger for modality because modality triggers are sparse for the overwhelming majority of sentences. We investigate an approach to automatically training a modality tagger where we first gathered sentences based on a high-recall simple rule-based modality tagger and then provided these sentences to Mechanical Turk annotators for further annotation. We used the resulting set of training data to train a precise modality tagger using a multi-class SVM that delivers good performance.
* In Proceedings of the Workshop on Extra-Propositional Aspects of
Meaning in Computational Linguistics, pages 57-64, Jeju, Republic of Korea,
July 2012. Association for Computational Linguistics * 8 pages, 6 tables; appeared in Proceedings of the Workshop on
Extra-Propositional Aspects of Meaning in Computational Linguistics, July
2012; In Proceedings of the Workshop on Extra-Propositional Aspects of
Meaning in Computational Linguistics, pages 57-64, Jeju, Republic of Korea,
July 2012. Association for Computational Linguistics
View paper on