 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Unsupervised Pre-training in Light of Recent Advances
Paper and Code


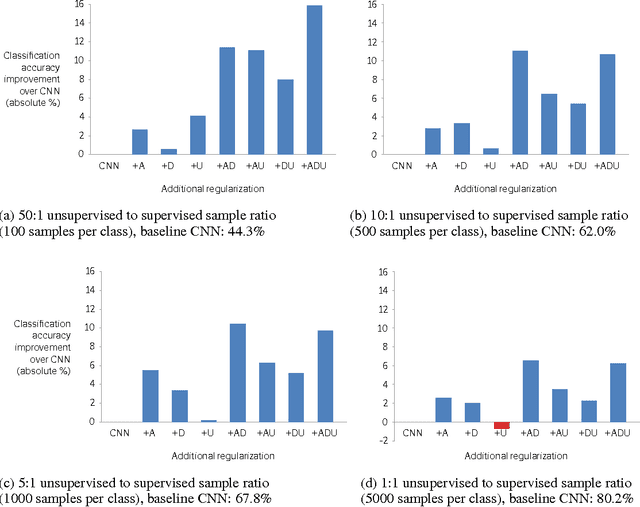

Convolutional neural networks perform well on object recognition because of a number of recent advances: rectified linear units (ReLUs), data augmentation, dropout, and large labelled datasets. Unsupervised data has been proposed as another way to improve performance. Unfortunately, unsupervised pre-training is not used by state-of-the-art methods leading to the following question: Is unsupervised pre-training still useful given recent advances? If so, when? We answer this in three parts: we 1) develop an unsupervised method that incorporates ReLUs and recent unsupervised regularization techniques, 2) analyze the benefits of unsupervised pre-training compared to data augmentation and dropout on CIFAR-10 while varying the ratio of unsupervised to supervised samples, 3) verify our findings on STL-10. We discover unsupervised pre-training, as expected, helps when the ratio of unsupervised to supervised samples is high, and surprisingly, hurts when the ratio is low. We also use unsupervised pre-training with additional color augmentation to achieve near state-of-the-art performance on STL-10.