 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinkage Optimized Directed Information using Pictorial Structures for Action Recognition
Paper and Code
Apr 12, 2014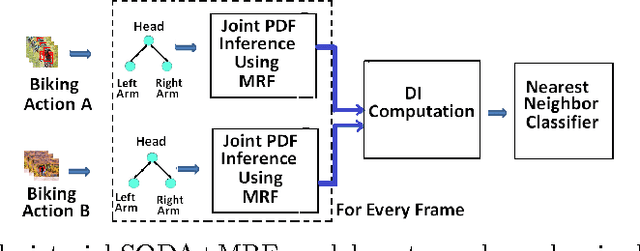
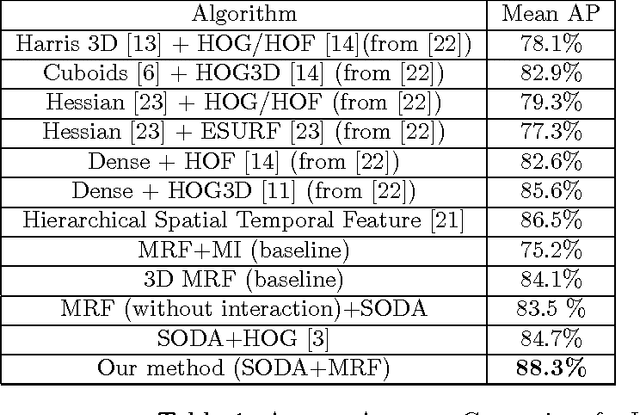
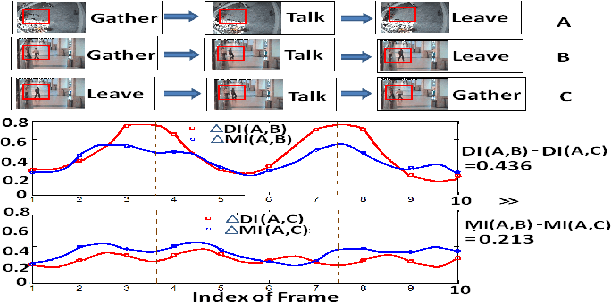
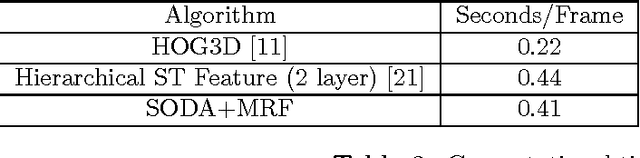
In this paper, we propose a novel action recognition framework. The method uses pictorial structures and shrinkage optimized directed information assessment (SODA) coupled with Markov Random Fields called SODA+MRF to model the directional temporal dependency and bidirectional spatial dependency. As a variant of mutual information, directional information captures the directional information flow and temporal structure of video sequences across frames. Meanwhile, within each frame, Markov random fields are utilized to model the spatial relations among different parts of a human body and the body parts of different people. The proposed SODA+MRF model is robust to view point transformations and detect complex interactions accurately. We compare the proposed method against several baseline methods to highlight the effectiveness of the SODA+MRF model. We demonstrate that our algorithm has superior action recognition performance on the UCF action recognition dataset, the Olympic sports dataset and the collective activity dataset over several state-of-the-art methods.