 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling sequential data using higher-order relational features and predictive training
Paper and Code
Feb 10, 2014

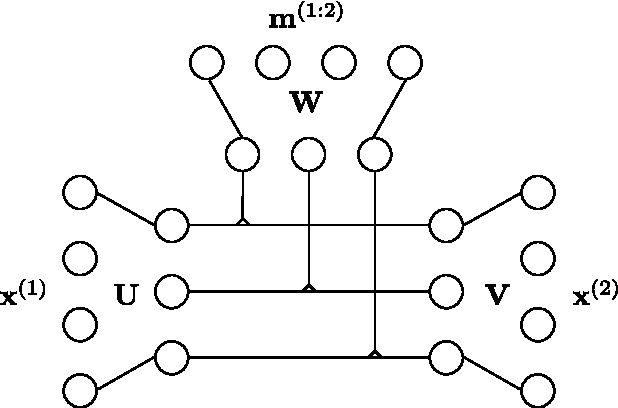
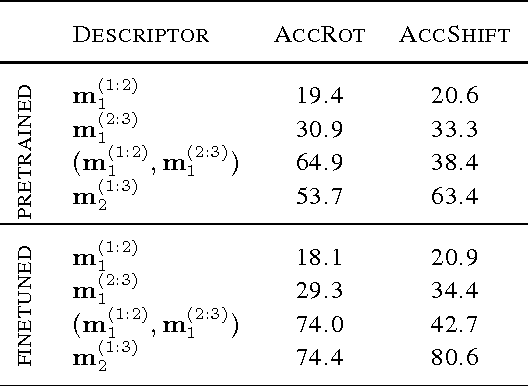
Bi-linear feature learning models, like the gated autoencoder, were proposed as a way to model relationships between frames in a video. By minimizing reconstruction error of one frame, given the previous frame, these models learn "mapping units" that encode the transformations inherent in a sequence, and thereby learn to encode motion. In this work we extend bi-linear models by introducing "higher-order mapping units" that allow us to encode transformations between frames and transformations between transformations. We show that this makes it possible to encode temporal structure that is more complex and longer-range than the structure captured within standard bi-linear models. We also show that a natural way to train the model is by replacing the commonly used reconstruction objective with a prediction objective which forces the model to correctly predict the evolution of the input multiple steps into the future. Learning can be achieved by back-propagating the multi-step prediction through time. We test the model on various temporal prediction tasks, and show that higher-order mappings and predictive training both yield a significant improvement over bi-linear models in terms of prediction accuracy.