 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Smashing
Paper and Code
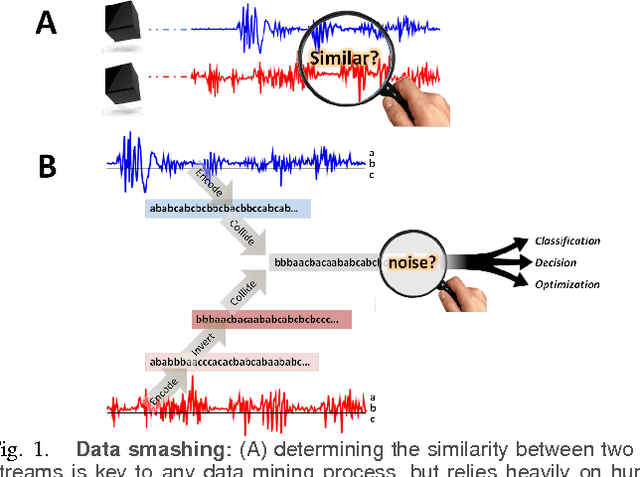
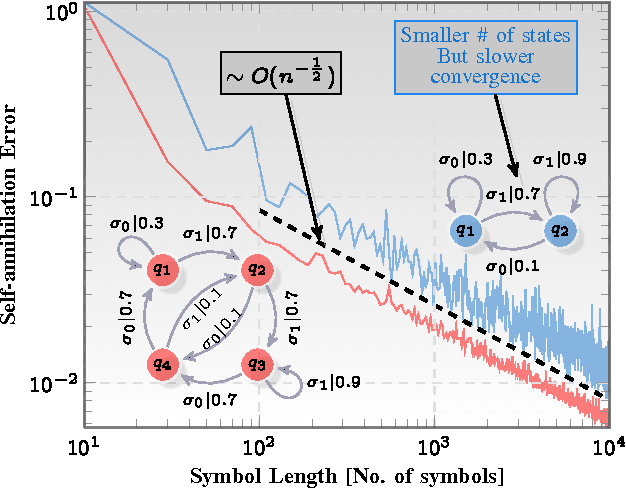
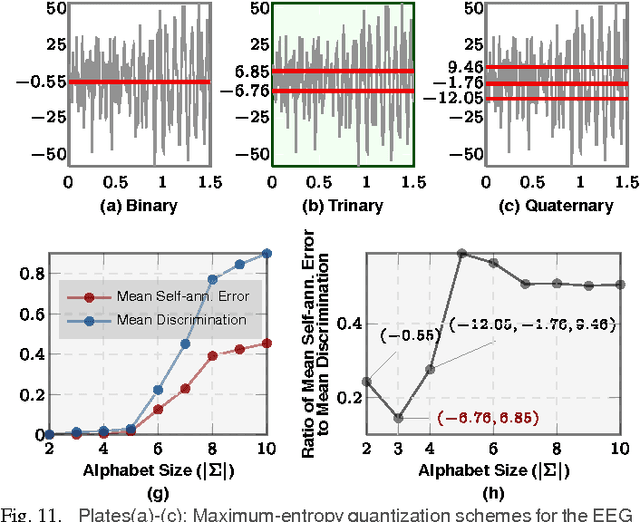
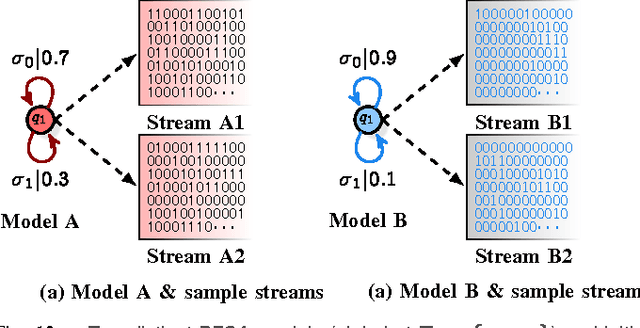
Investigation of the underlying physics or biology from empirical data requires a quantifiable notion of similarity - when do two observed data sets indicate nearly identical generating processes, and when they do not. The discriminating characteristics to look for in data is often determined by heuristics designed by experts, $e.g.$, distinct shapes of "folded" lightcurves may be used as "features" to classify variable stars, while determination of pathological brain states might require a Fourier analysis of brainwave activity. Finding good features is non-trivial. Here, we propose a universal solution to this problem: we delineate a principle for quantifying similarity between sources of arbitrary data streams, without a priori knowledge, features or training. We uncover an algebraic structure on a space of symbolic models for quantized data, and show that such stochastic generators may be added and uniquely inverted; and that a model and its inverse always sum to the generator of flat white noise. Therefore, every data stream has an anti-stream: data generated by the inverse model. Similarity between two streams, then, is the degree to which one, when summed to the other's anti-stream, mutually annihilates all statistical structure to noise. We call this data smashing. We present diverse applications, including disambiguation of brainwaves pertaining to epileptic seizures, detection of anomalous cardiac rhythms, and classification of astronomical objects from raw photometry. In our examples, the data smashing principle, without access to any domain knowledge, meets or exceeds the performance of specialized algorithms tuned by domain experts.