 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn b-bit min-wise hashing for large-scale regression and classification with sparse data
Paper and Code
Feb 26, 2018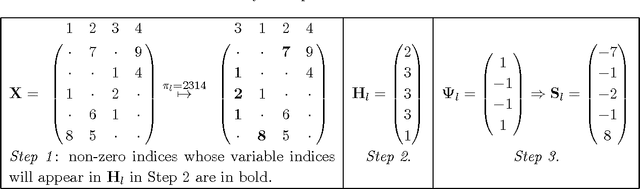
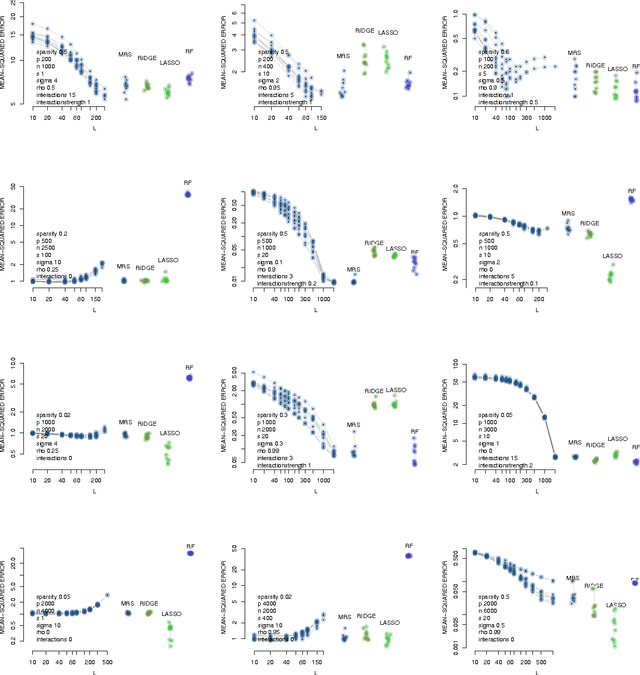
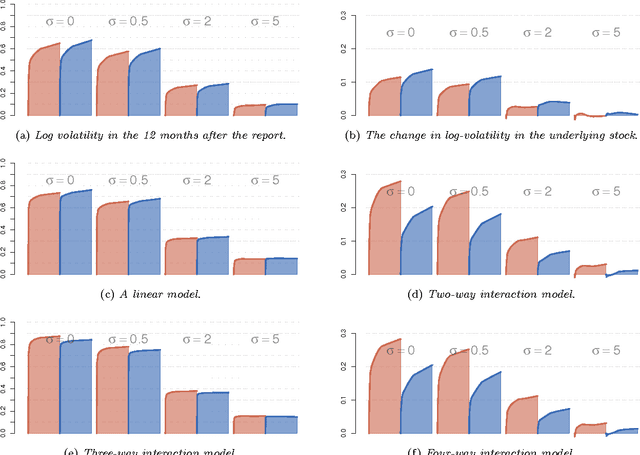
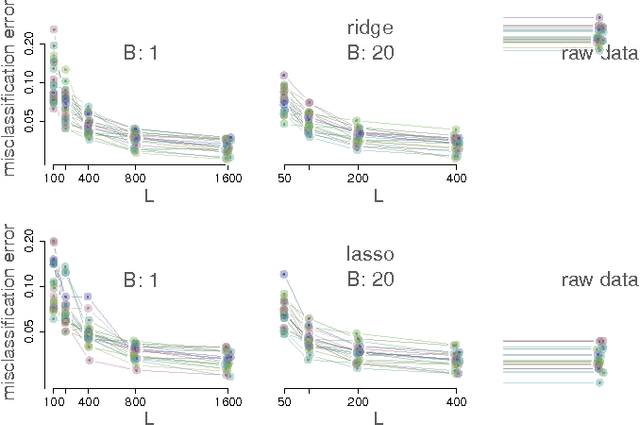
Large-scale regression problems where both the number of variables, $p$, and the number of observations, $n$, may be large and in the order of millions or more, are becoming increasingly more common. Typically the data are sparse: only a fraction of a percent of the entries in the design matrix are non-zero. Nevertheless, often the only computationally feasible approach is to perform dimension reduction to obtain a new design matrix with far fewer columns and then work with this compressed data. $b$-bit min-wise hashing (Li and Konig, 2011) is a promising dimension reduction scheme for sparse matrices which produces a set of random features such that regression on the resulting design matrix approximates a kernel regression with the resemblance kernel. In this work, we derive bounds on the prediction error of such regressions. For both linear and logistic models we show that the average prediction error vanishes asymptotically as long as $q \|\beta^*\|_2^2 /n \rightarrow 0$, where $q$ is the average number of non-zero entries in each row of the design matrix and $\beta^*$ is the coefficient of the linear predictor. We also show that ordinary least squares or ridge regression applied to the reduced data can in fact allow us fit more flexible models. We obtain non-asymptotic prediction error bounds for interaction models and for models where an unknown row normalisation must be applied in order for the signal to be linear in the predictors.