 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Physical Connections: Tree Models in Human Pose Estimation
Paper and Code
May 10, 2013
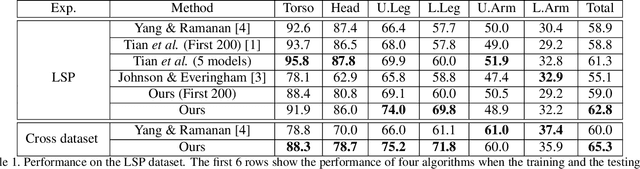
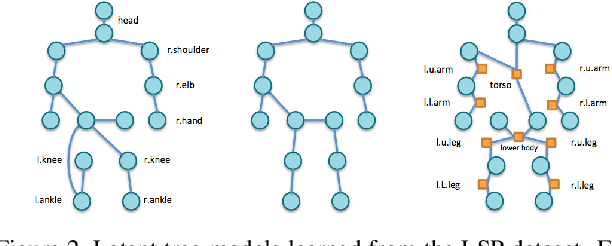

Simple tree models for articulated objects prevails in the last decade. However, it is also believed that these simple tree models are not capable of capturing large variations in many scenarios, such as human pose estimation. This paper attempts to address three questions: 1) are simple tree models sufficient? more specifically, 2) how to use tree models effectively in human pose estimation? and 3) how shall we use combined parts together with single parts efficiently? Assuming we have a set of single parts and combined parts, and the goal is to estimate a joint distribution of their locations. We surprisingly find that no latent variables are introduced in the Leeds Sport Dataset (LSP) during learning latent trees for deformable model, which aims at approximating the joint distributions of body part locations using minimal tree structure. This suggests one can straightforwardly use a mixed representation of single and combined parts to approximate their joint distribution in a simple tree model. As such, one only needs to build Visual Categories of the combined parts, and then perform inference on the learned latent tree. Our method outperformed the state of the art on the LSP, both in the scenarios when the training images are from the same dataset and from the PARSE dataset. Experiments on animal images from the VOC challenge further support our findings.