 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Symbols for Parsing Human Poses in Images
Paper and Code
Apr 23, 2013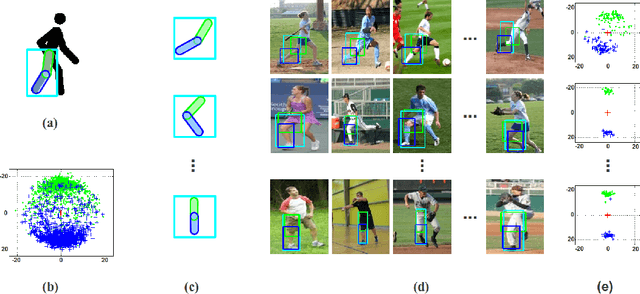
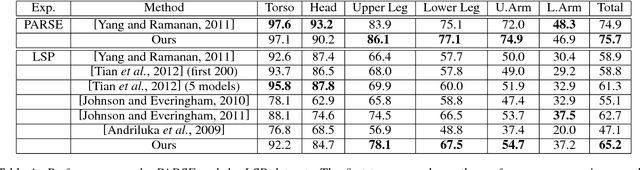

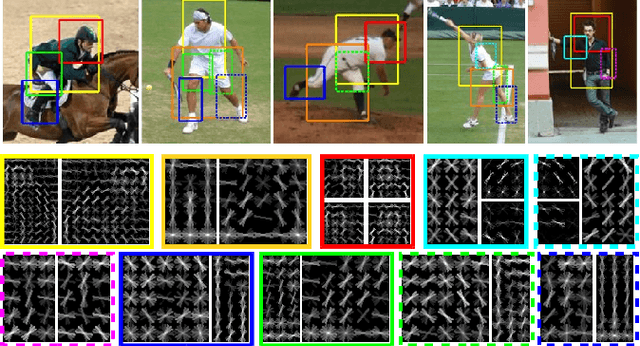
Parsing human poses in images is fundamental in extracting critical visual information for artificial intelligent agents. Our goal is to learn self-contained body part representations from images, which we call visual symbols, and their symbol-wise geometric contexts in this parsing process. Each symbol is individually learned by categorizing visual features leveraged by geometric information. In the categorization, we use Latent Support Vector Machine followed by an efficient cross validation procedure to learn visual symbols. Then, these symbols naturally define geometric contexts of body parts in a fine granularity. When the structure of the compositional parts is a tree, we derive an efficient approach to estimating human poses in images. Experiments on two large datasets suggest our approach outperforms state of the art methods.