Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded regret in stochastic multi-armed bandits
Paper and Code
Feb 12, 2013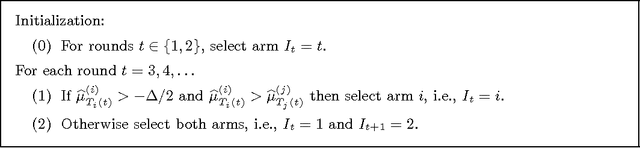

We study the stochastic multi-armed bandit problem when one knows the value $\mu^{(\star)}$ of an optimal arm, as a well as a positive lower bound on the smallest positive gap $\Delta$. We propose a new randomized policy that attains a regret {\em uniformly bounded over time} in this setting. We also prove several lower bounds, which show in particular that bounded regret is not possible if one only knows $\Delta$, and bounded regret of order $1/\Delta$ is not possible if one only knows $\mu^{(\star)}$
View paper on