 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Optimizing Recurrent Networks
Paper and Code
Dec 14, 2012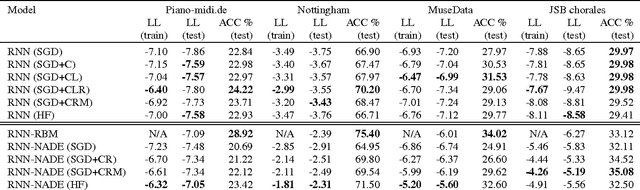
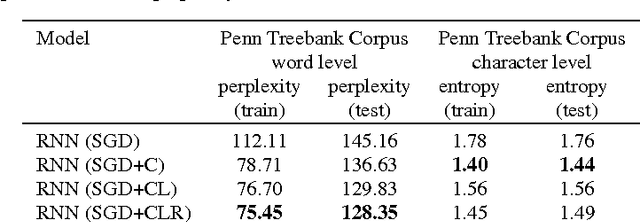
After a more than decade-long period of relatively little research activity in the area of recurrent neural networks, several new developments will be reviewed here that have allowed substantial progress both in understanding and in technical solutions towards more efficient training of recurrent networks. These advances have been motivated by and related to the optimization issues surrounding deep learning. Although recurrent networks are extremely powerful in what they can in principle represent in terms of modelling sequences,their training is plagued by two aspects of the same issue regarding the learning of long-term dependencies. Experiments reported here evaluate the use of clipping gradients, spanning longer time ranges with leaky integration, advanced momentum techniques, using more powerful output probability models, and encouraging sparser gradients to help symmetry breaking and credit assignment. The experiments are performed on text and music data and show off the combined effects of these techniques in generally improving both training and test error.