 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fast Cauchy Transform and Faster Robust Linear Regression
Paper and Code
Apr 05, 2014
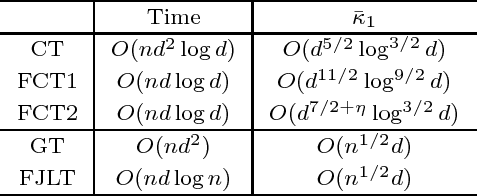


We provide fast algorithms for overconstrained $\ell_p$ regression and related problems: for an $n\times d$ input matrix $A$ and vector $b\in\mathbb{R}^n$, in $O(nd\log n)$ time we reduce the problem $\min_{x\in\mathbb{R}^d} \|Ax-b\|_p$ to the same problem with input matrix $\tilde A$ of dimension $s \times d$ and corresponding $\tilde b$ of dimension $s\times 1$. Here, $\tilde A$ and $\tilde b$ are a coreset for the problem, consisting of sampled and rescaled rows of $A$ and $b$; and $s$ is independent of $n$ and polynomial in $d$. Our results improve on the best previous algorithms when $n\gg d$, for all $p\in[1,\infty)$ except $p=2$. We also provide a suite of improved results for finding well-conditioned bases via ellipsoidal rounding, illustrating tradeoffs between running time and conditioning quality, including a one-pass conditioning algorithm for general $\ell_p$ problems. We also provide an empirical evaluation of implementations of our algorithms for $p=1$, comparing them with related algorithms. Our empirical results show that, in the asymptotic regime, the theory is a very good guide to the practical performance of these algorithms. Our algorithms use our faster constructions of well-conditioned bases for $\ell_p$ spaces and, for $p=1$, a fast subspace embedding of independent interest that we call the Fast Cauchy Transform: a distribution over matrices $\Pi:\mathbb{R}^n\mapsto \mathbb{R}^{O(d\log d)}$, found obliviously to $A$, that approximately preserves the $\ell_1$ norms: that is, with large probability, simultaneously for all $x$, $\|Ax\|_1 \approx \|\Pi Ax\|_1$, with distortion $O(d^{2+\eta})$, for an arbitrarily small constant $\eta>0$; and, moreover, $\Pi A$ can be computed in $O(nd\log d)$ time. The techniques underlying our Fast Cauchy Transform include fast Johnson-Lindenstrauss transforms, low-coherence matrices, and rescaling by Cauchy random variables.