 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Randomized Mirror Descent Algorithm for Large Scale Multiple Kernel Learning
Paper and Code
Jan 07, 2013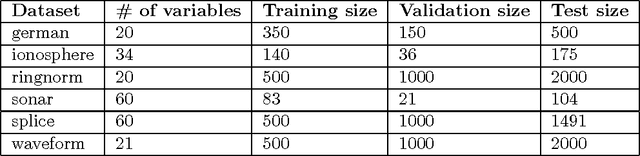
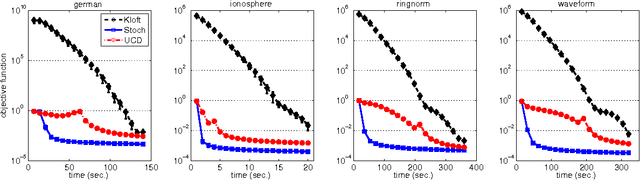
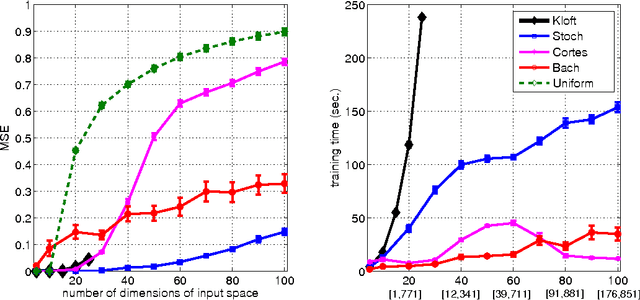
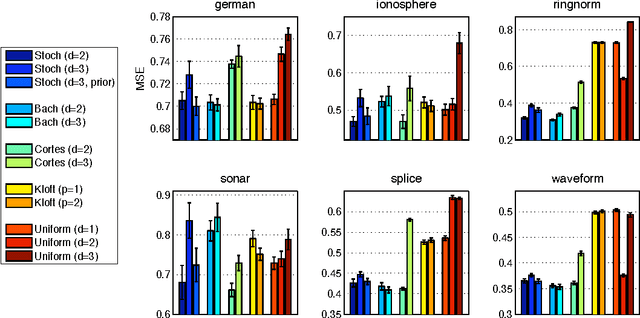
We consider the problem of simultaneously learning to linearly combine a very large number of kernels and learn a good predictor based on the learnt kernel. When the number of kernels $d$ to be combined is very large, multiple kernel learning methods whose computational cost scales linearly in $d$ are intractable. We propose a randomized version of the mirror descent algorithm to overcome this issue, under the objective of minimizing the group $p$-norm penalized empirical risk. The key to achieve the required exponential speed-up is the computationally efficient construction of low-variance estimates of the gradient. We propose importance sampling based estimates, and find that the ideal distribution samples a coordinate with a probability proportional to the magnitude of the corresponding gradient. We show the surprising result that in the case of learning the coefficients of a polynomial kernel, the combinatorial structure of the base kernels to be combined allows the implementation of sampling from this distribution to run in $O(\log(d))$ time, making the total computational cost of the method to achieve an $\epsilon$-optimal solution to be $O(\log(d)/\epsilon^2)$, thereby allowing our method to operate for very large values of $d$. Experiments with simulated and real data confirm that the new algorithm is computationally more efficient than its state-of-the-art alternatives.