Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multicore Collaborative Filtering
Paper and Code
Aug 17, 2011
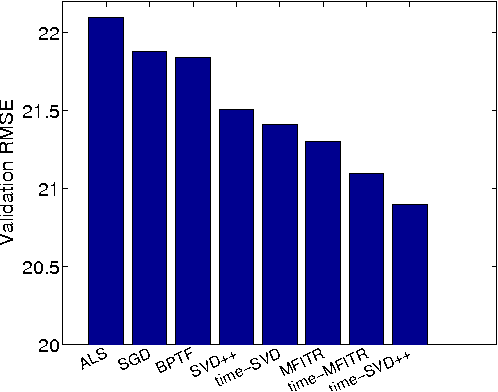

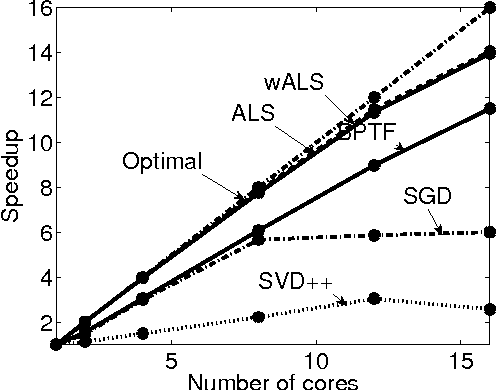
This paper describes the solution method taken by LeBuSiShu team for track1 in ACM KDD CUP 2011 contest (resulting in the 5th place). We identified two main challenges: the unique item taxonomy characteristics as well as the large data set size.To handle the item taxonomy, we present a novel method called Matrix Factorization Item Taxonomy Regularization (MFITR). MFITR obtained the 2nd best prediction result out of more then ten implemented algorithms. For rapidly computing multiple solutions of various algorithms, we have implemented an open source parallel collaborative filtering library on top of the GraphLab machine learning framework. We report some preliminary performance results obtained using the BlackLight supercomputer.
* In ACM KDD CUP Workshop 2011
View paper on