 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concise yet Effective model for Non-Aligned Incomplete Multi-view and Missing Multi-label Learning
Paper and Code
May 03, 2020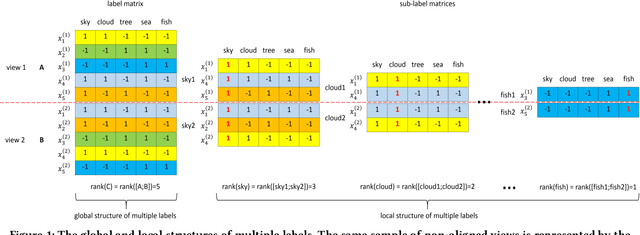
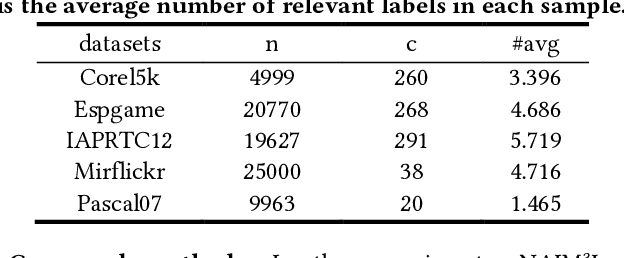
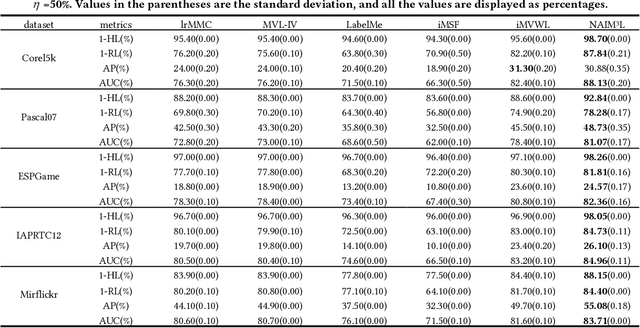
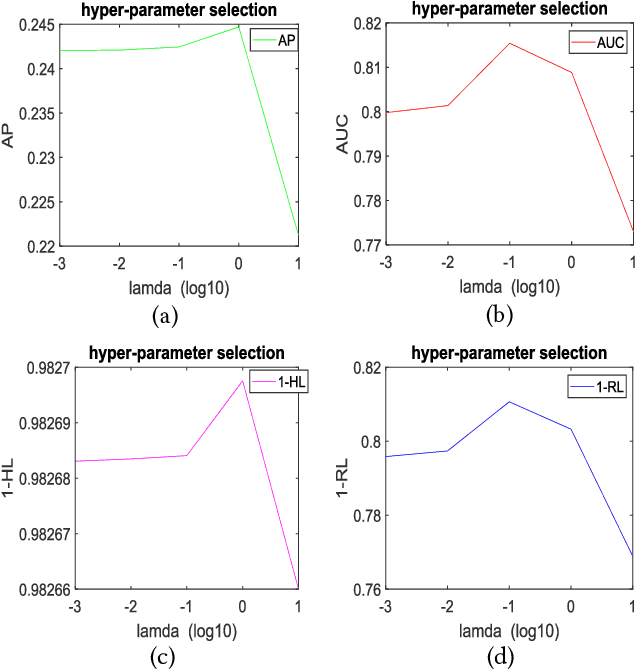
In real-world applications, learning from data with multi-view and multi-label inevitably confronts with three challenges: missing labels, incomplete views, and non-aligned views. Existing methods mainly concern the first two and commonly need multiple assumptions in attacking them, making even state-of-the-arts also involve at least two explicit hyper-parameters in their objectives such that model selection is quite difficult. More toughly, these will encounter a failure in dealing with the third challenge, let alone address the three challenges jointly. In this paper, our goal is to meet all of them by presenting a concise yet effective model with only one hyper-parameter in modeling under the least assumption. To make our model more discriminative, we exploit not only the consensus of multiple views but also the global and local structures among multiple labels. More specifically, we introduce an indicator matrix to tackle the first two challenges in a regression manner while align the same individual label and all labels of different views in a common label space to battle the third challenge. During our alignment, we characterize specially the global and the local structures of multiple labels with high-rank and low-rank, respectively. Consequently, the regularization terms involved in modeling are integrated by a single hyper-parameter. Even without view-alignment, it is still confirmed that our method achieves better performance on five real datasets compared to state-of-the-arts.