 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Batch-Insensitive Dynamic GNN Approach to Address Temporal Discontinuity in Graph Streams
Paper and Code
Jun 24, 2025

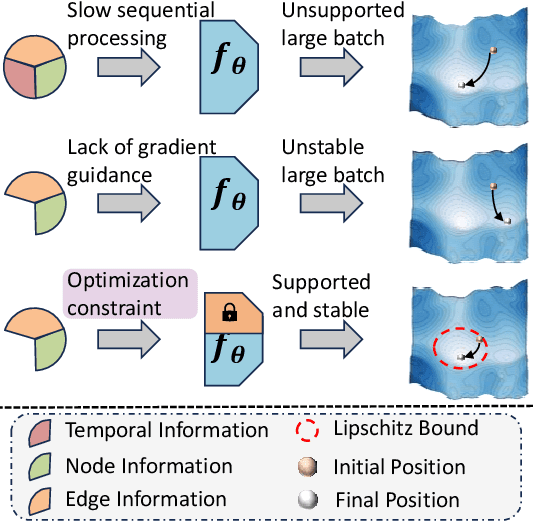

In dynamic graphs, preserving temporal continuity is critical. However, Memory-based Dynamic Graph Neural Networks (MDGNNs) trained with large batches often disrupt event sequences, leading to temporal information loss. This discontinuity not only deteriorates temporal modeling but also hinders optimization by increasing the difficulty of parameter convergence. Our theoretical study quantifies this through a Lipschitz upper bound, showing that large batch sizes enlarge the parameter search space. In response, we propose BADGNN, a novel batch-agnostic framework consisting of two core components: (1) Temporal Lipschitz Regularization (TLR) to control parameter search space expansion, and (2) Adaptive Attention Adjustment (A3) to alleviate attention distortion induced by both regularization and batching. Empirical results on three benchmark datasets show that BADGNN maintains strong performance while enabling significantly larger batch sizes and faster training compared to TGN. Our code is available at Code: https://anonymous.4open.science/r/TGN_Lipichitz-C033/.