 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval, Refinement, and Ranking for Text-to-Video Generation via Prompt Optimization and Test-Time Scaling
Mar 02, 2026While large-scale datasets have driven significant progress in Text-to-Video (T2V) generative models, these models remain highly sensitive to input prompts, demonstrating that prompt design is critical to generation quality. Current methods for improving video output often fall short: they either depend on complex, post-editing models, risking the introduction of artifacts, or require expensive fine-tuning of the core generator, which severely limits both scalability and accessibility. In this work, we introduce 3R, a novel RAG based prompt optimization framework. 3R utilizes the power of current state-of-the-art T2V diffusion model and vision language model. It can be used with any T2V model without any kind of model training. The framework leverages three key strategies: RAG-based modifiers extraction for enriched contextual grounding, diffusion-based Preference Optimization for aligning outputs with human preferences, and temporal frame interpolation for producing temporally consistent visual contents. Together, these components enable more accurate, efficient, and contextually aligned text-to-video generation. Experimental results demonstrate the efficacy of 3R in enhancing the static fidelity and dynamic coherence of generated videos, underscoring the importance of optimizing user prompts.
ROSER: Few-Shot Robotic Sequence Retrieval for Scalable Robot Learning
Mar 02, 2026A critical bottleneck in robot learning is the scarcity of task-labeled, segmented training data, despite the abundance of large-scale robotic datasets recorded as long, continuous interaction logs. Existing datasets contain vast amounts of diverse behaviors, yet remain structurally incompatible with modern learning frameworks that require cleanly segmented, task-specific trajectories. We address this data utilization crisis by formalizing robotic sequence retrieval: the task of extracting reusable, task-centric segments from unlabeled logs using only a few reference examples. We introduce ROSER, a lightweight few-shot retrieval framework that learns task-agnostic metric spaces over temporal windows, enabling accurate retrieval with as few as 3-5 demonstrations, without any task-specific training required. To validate our approach, we establish comprehensive evaluation protocols and benchmark ROSER against classical alignment methods, learned embeddings, and language model baselines across three large-scale datasets (e.g., LIBERO, DROID, and nuScenes). Our experiments demonstrate that ROSER consistently outperforms all prior methods in both accuracy and efficiency, achieving sub-millisecond per-match inference while maintaining superior distributional alignment. By reframing data curation as few-shot retrieval, ROSER provides a practical pathway to unlock underutilized robotic datasets, fundamentally improving data availability for robot learning.
LVLane: Deep Learning for Lane Detection and Classification in Challenging Conditions
Jul 13, 2023



Lane detection plays a pivotal role in the field of autonomous vehicles and advanced driving assistant systems (ADAS). Over the years, numerous algorithms have emerged, spanning from rudimentary image processing techniques to sophisticated deep neural networks. The performance of deep learning-based models is highly dependent on the quality of their training data. Consequently, these models often experience a decline in performance when confronted with challenging scenarios such as extreme lighting conditions, partially visible lane markings, and sparse lane markings like Botts' dots. To address this, we present an end-to-end lane detection and classification system based on deep learning methodologies. In our study, we introduce a unique dataset meticulously curated to encompass scenarios that pose significant challenges for state-of-the-art (SOTA) models. Through fine-tuning selected models, we aim to achieve enhanced localization accuracy. Moreover, we propose a CNN-based classification branch, seamlessly integrated with the detector, facilitating the identification of distinct lane types. This architecture enables informed lane-changing decisions and empowers more resilient ADAS capabilities. We also investigate the effect of using mixed precision training and testing on different models and batch sizes. Experimental evaluations conducted on the widely-used TuSimple dataset, Caltech lane dataset, and our LVLane dataset demonstrate the effectiveness of our model in accurately detecting and classifying lanes amidst challenging scenarios. Our method achieves state-of-the-art classification results on the TuSimple dataset. The code of the work will be published upon the acceptance of the paper.
* 8 pages
A Real-Time Wrong-Way Vehicle Detection Based on YOLO and Centroid Tracking
Oct 19, 2022
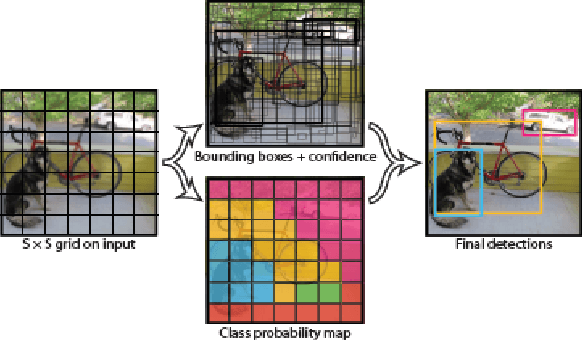

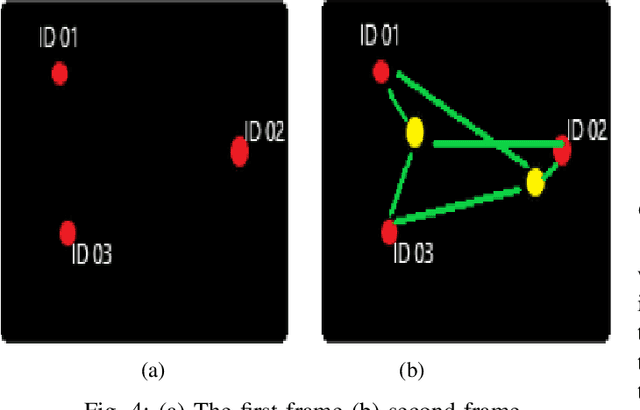
Wrong-way driving is one of the main causes of road accidents and traffic jam all over the world. By detecting wrong-way vehicles, the number of accidents can be minimized and traffic jam can be reduced. With the increasing popularity of real-time traffic management systems and due to the availability of cheaper cameras, the surveillance video has become a big source of data. In this paper, we propose an automatic wrong-way vehicle detection system from on-road surveillance camera footage. Our system works in three stages: the detection of vehicles from the video frame by using the You Only Look Once (YOLO) algorithm, track each vehicle in a specified region of interest using centroid tracking algorithm and detect the wrong-way driving vehicles. YOLO is very accurate in object detection and the centroid tracking algorithm can track any moving object efficiently. Experiment with some traffic videos shows that our proposed system can detect and identify any wrong-way vehicle in different light and weather conditions. The system is very simple and easy to implement.
* 5 pages
An enhanced method of initial cluster center selection for K-means algorithm
Oct 18, 2022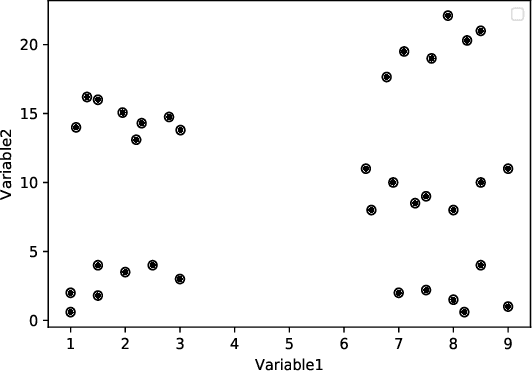
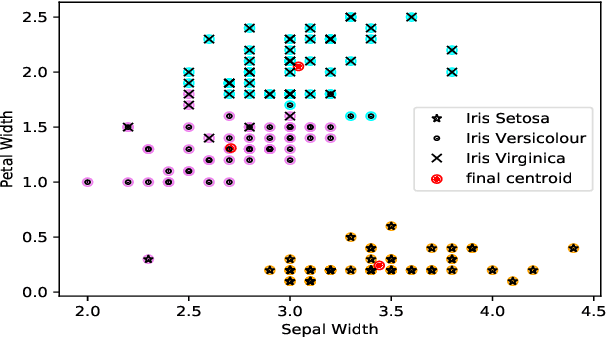
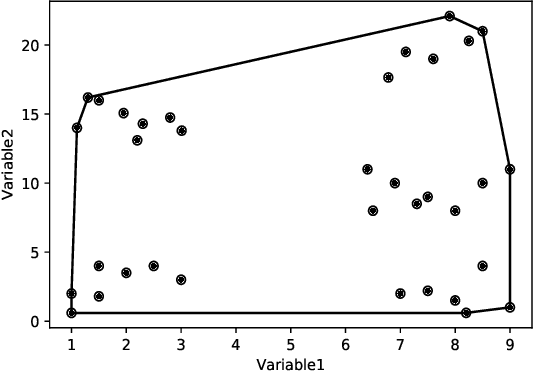
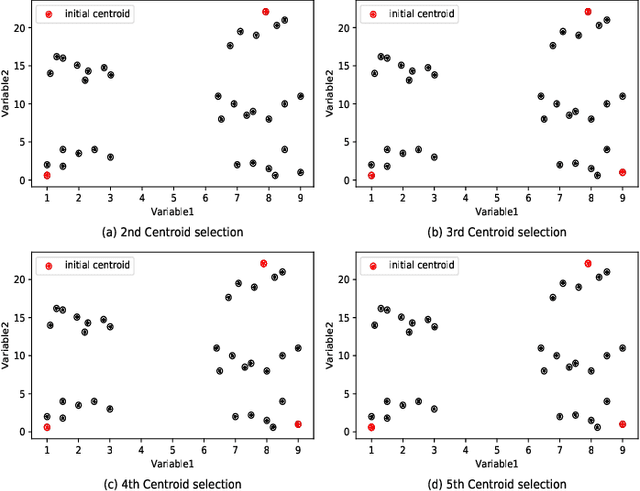
Clustering is one of the widely used techniques to find out patterns from a dataset that can be applied in different applications or analyses. K-means, the most popular and simple clustering algorithm, might get trapped into local minima if not properly initialized and the initialization of this algorithm is done randomly. In this paper, we propose a novel approach to improve initial cluster selection for K-means algorithm. This algorithm is based on the fact that the initial centroids must be well separated from each other since the final clusters are separated groups in feature space. The Convex Hull algorithm facilitates the computing of the first two centroids and the remaining ones are selected according to the distance from previously selected centers. To ensure the selection of one center per cluster, we use the nearest neighbor technique. To check the robustness of our proposed algorithm, we consider several real-world datasets. We obtained only 7.33%, 7.90%, and 0% clustering error in Iris, Letter, and Ruspini data respectively which proves better performance than other existing systems. The results indicate that our proposed method outperforms the conventional K means approach by accelerating the computation when the number of clusters is greater than 2.
* 6 pages