 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Explainer: Interactive Learning of Text-Generative Models
Aug 08, 2024
Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model. Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures. It runs a live GPT-2 instance locally in the user's browser, empowering users to experiment with their own input and observe in real-time how the internal components and parameters of the Transformer work together to predict the next tokens. Our tool requires no installation or special hardware, broadening the public's education access to modern generative AI techniques. Our open-sourced tool is available at https://poloclub.github.io/transformer-explainer/. A video demo is available at https://youtu.be/ECR4oAwocjs.
MeMemo: On-device Retrieval Augmentation for Private and Personalized Text Generation
Jul 02, 2024Retrieval-augmented text generation (RAG) addresses the common limitations of large language models (LLMs), such as hallucination, by retrieving information from an updatable external knowledge base. However, existing approaches often require dedicated backend servers for data storage and retrieval, thereby limiting their applicability in use cases that require strict data privacy, such as personal finance, education, and medicine. To address the pressing need for client-side dense retrieval, we introduce MeMemo, the first open-source JavaScript toolkit that adapts the state-of-the-art approximate nearest neighbor search technique HNSW to browser environments. Developed with modern and native Web technologies, such as IndexedDB and Web Workers, our toolkit leverages client-side hardware capabilities to enable researchers and developers to efficiently search through millions of high-dimensional vectors in the browser. MeMemo enables exciting new design and research opportunities, such as private and personalized content creation and interactive prototyping, as demonstrated in our example application RAG Playground. Reflecting on our work, we discuss the opportunities and challenges for on-device dense retrieval. MeMemo is available at https://github.com/poloclub/mememo.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
LLM Attributor: Interactive Visual Attribution for LLM Generation
Apr 01, 2024

While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.
Farsight: Fostering Responsible AI Awareness During AI Application Prototyping
Feb 23, 2024



Prompt-based interfaces for Large Language Models (LLMs) have made prototyping and building AI-powered applications easier than ever before. However, identifying potential harms that may arise from AI applications remains a challenge, particularly during prompt-based prototyping. To address this, we present Farsight, a novel in situ interactive tool that helps people identify potential harms from the AI applications they are prototyping. Based on a user's prompt, Farsight highlights news articles about relevant AI incidents and allows users to explore and edit LLM-generated use cases, stakeholders, and harms. We report design insights from a co-design study with 10 AI prototypers and findings from a user study with 42 AI prototypers. After using Farsight, AI prototypers in our user study are better able to independently identify potential harms associated with a prompt and find our tool more useful and usable than existing resources. Their qualitative feedback also highlights that Farsight encourages them to focus on end-users and think beyond immediate harms. We discuss these findings and reflect on their implications for designing AI prototyping experiences that meaningfully engage with AI harms. Farsight is publicly accessible at: https://PAIR-code.github.io/farsight.
Wordflow: Social Prompt Engineering for Large Language Models
Jan 25, 2024



Large language models (LLMs) require well-crafted prompts for effective use. Prompt engineering, the process of designing prompts, is challenging, particularly for non-experts who are less familiar with AI technologies. While researchers have proposed techniques and tools to assist LLM users in prompt design, these works primarily target AI application developers rather than non-experts. To address this research gap, we propose social prompt engineering, a novel paradigm that leverages social computing techniques to facilitate collaborative prompt design. To investigate social prompt engineering, we introduce Wordflow, an open-source and social text editor that enables everyday users to easily create, run, share, and discover LLM prompts. Additionally, by leveraging modern web technologies, Wordflow allows users to run LLMs locally and privately in their browsers. Two usage scenarios highlight how social prompt engineering and our tool can enhance laypeople's interaction with LLMs. Wordflow is publicly accessible at https://poloclub.github.io/wordflow.
REVAMP: Automated Simulations of Adversarial Attacks on Arbitrary Objects in Realistic Scenes
Oct 18, 2023

Deep Learning models, such as those used in an autonomous vehicle are vulnerable to adversarial attacks where an attacker could place an adversarial object in the environment, leading to mis-classification. Generating these adversarial objects in the digital space has been extensively studied, however successfully transferring these attacks from the digital realm to the physical realm has proven challenging when controlling for real-world environmental factors. In response to these limitations, we introduce REVAMP, an easy-to-use Python library that is the first-of-its-kind tool for creating attack scenarios with arbitrary objects and simulating realistic environmental factors, lighting, reflection, and refraction. REVAMP enables researchers and practitioners to swiftly explore various scenarios within the digital realm by offering a wide range of configurable options for designing experiments and using differentiable rendering to reproduce physically plausible adversarial objects. We will demonstrate and invite the audience to try REVAMP to produce an adversarial texture on a chosen object while having control over various scene parameters. The audience will choose a scene, an object to attack, the desired attack class, and the number of camera positions to use. Then, in real time, we show how this altered texture causes the chosen object to be mis-classified, showcasing the potential of REVAMP in real-world scenarios. REVAMP is open-source and available at https://github.com/poloclub/revamp.
WizMap: Scalable Interactive Visualization for Exploring Large Machine Learning Embeddings
Jun 15, 2023
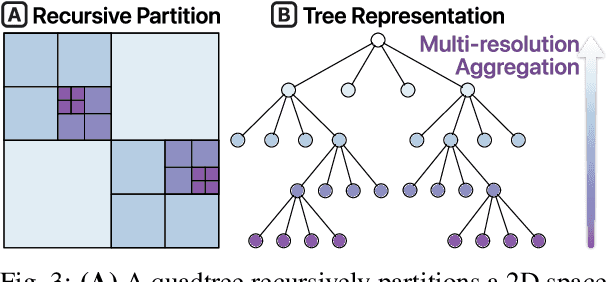
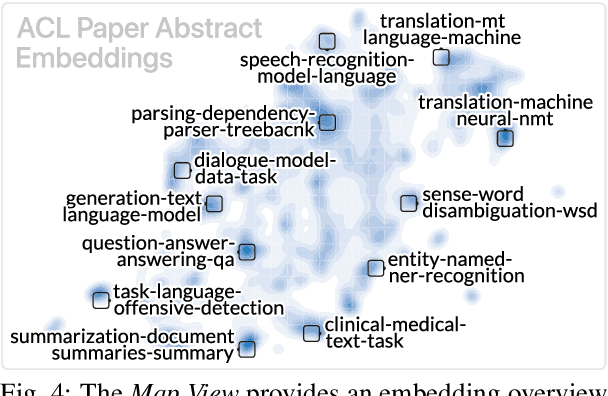

Machine learning models often learn latent embedding representations that capture the domain semantics of their training data. These embedding representations are valuable for interpreting trained models, building new models, and analyzing new datasets. However, interpreting and using embeddings can be challenging due to their opaqueness, high dimensionality, and the large size of modern datasets. To tackle these challenges, we present WizMap, an interactive visualization tool to help researchers and practitioners easily explore large embeddings. With a novel multi-resolution embedding summarization method and a familiar map-like interaction design, WizMap enables users to navigate and interpret embedding spaces with ease. Leveraging modern web technologies such as WebGL and Web Workers, WizMap scales to millions of embedding points directly in users' web browsers and computational notebooks without the need for dedicated backend servers. WizMap is open-source and available at the following public demo link: https://poloclub.github.io/wizmap.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023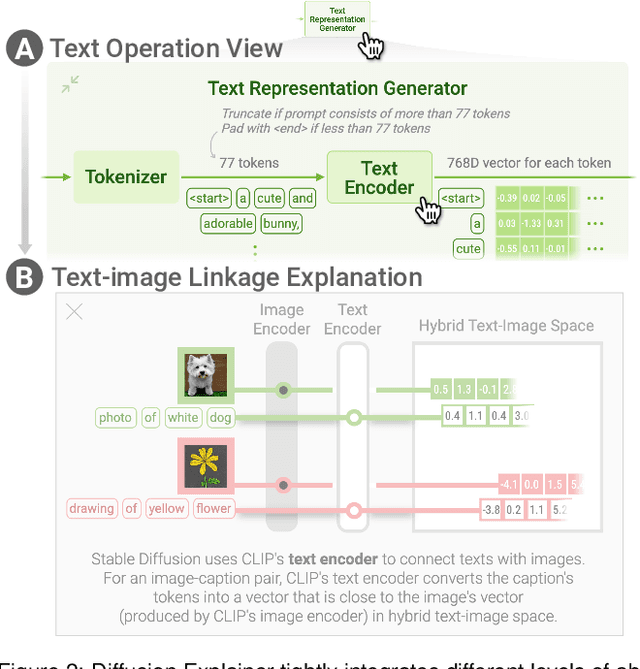
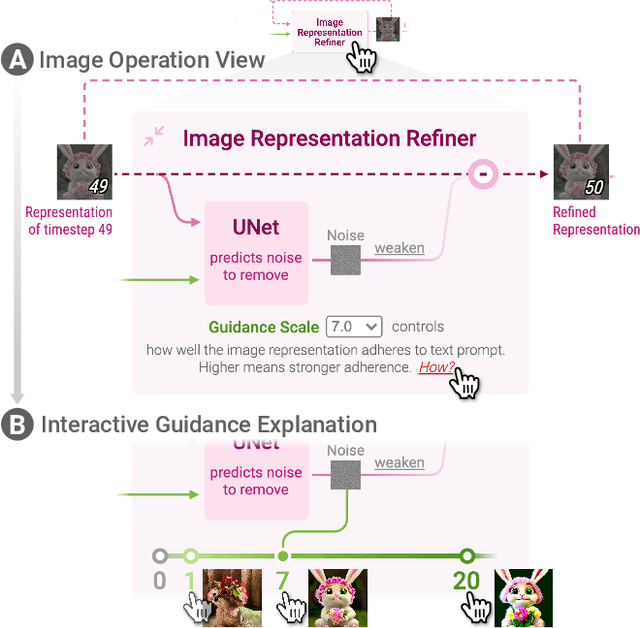
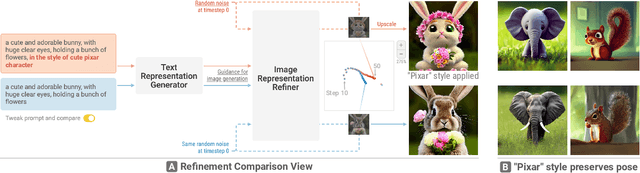
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
SuperNOVA: Design Strategies and Opportunities for Interactive Visualization in Computational Notebooks
May 04, 2023


Computational notebooks such as Jupyter Notebook have become data scientists' de facto programming environments. Many visualization researchers and practitioners have developed interactive visualization tools that support notebooks. However, little is known about the appropriate design of visual analytics (VA) tools in notebooks. To bridge this critical research gap, we investigate the design strategies in this space by analyzing 159 notebook VA tools and their users' feedback. Our analysis encompasses 62 systems from academic papers and 103 systems sourced from a pool of 55k notebooks containing interactive visualizations that we obtain via scraping 8.6 million notebooks on GitHub. We also examine findings from 15 user studies and user feedback in 379 GitHub issues. Through this work, we identify unique design opportunities and considerations for future notebook VA tools, such as using and manipulating multimodal data in notebooks as well as balancing the degree of visualization-notebook integration. Finally, we develop SuperNOVA, an open-source interactive tool to help researchers explore existing notebook VA tools and search for related work.