 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs meet open-world graph learning: a new perspective for unlabeled data uncertainty
May 21, 2025Recently, large language models (LLMs) have significantly advanced text-attributed graph (TAG) learning. However, existing methods inadequately handle data uncertainty in open-world scenarios, especially concerning limited labeling and unknown-class nodes. Prior solutions typically rely on isolated semantic or structural approaches for unknown-class rejection, lacking effective annotation pipelines. To address these limitations, we propose Open-world Graph Assistant (OGA), an LLM-based framework that combines adaptive label traceability, which integrates semantics and topology for unknown-class rejection, and a graph label annotator to enable model updates using newly annotated nodes. Comprehensive experiments demonstrate OGA's effectiveness and practicality.
Maximum Density Divergence for Domain Adaptation
Apr 27, 2020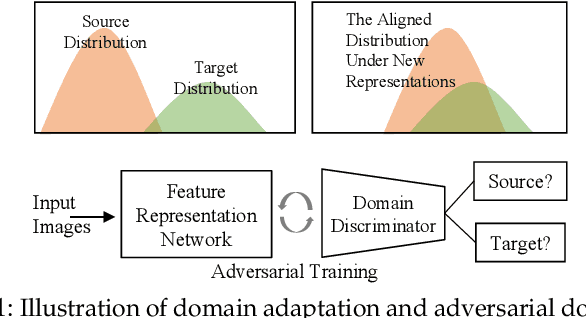
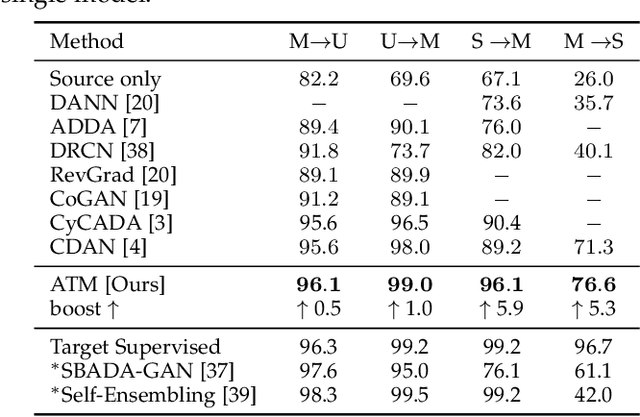
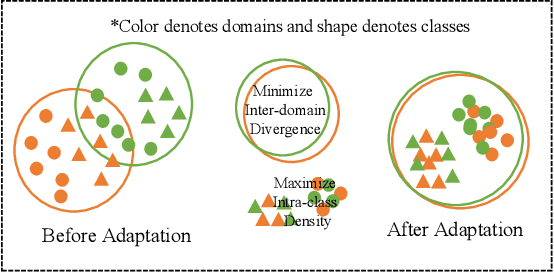
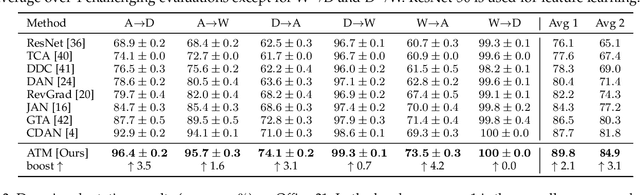
Unsupervised domain adaptation addresses the problem of transferring knowledge from a well-labeled source domain to an unlabeled target domain where the two domains have distinctive data distributions. Thus, the essence of domain adaptation is to mitigate the distribution divergence between the two domains. The state-of-the-art methods practice this very idea by either conducting adversarial training or minimizing a metric which defines the distribution gaps. In this paper, we propose a new domain adaptation method named Adversarial Tight Match (ATM) which enjoys the benefits of both adversarial training and metric learning. Specifically, at first, we propose a novel distance loss, named Maximum Density Divergence (MDD), to quantify the distribution divergence. MDD minimizes the inter-domain divergence ("match" in ATM) and maximizes the intra-class density ("tight" in ATM). Then, to address the equilibrium challenge issue in adversarial domain adaptation, we consider leveraging the proposed MDD into adversarial domain adaptation framework. At last, we tailor the proposed MDD as a practical learning loss and report our ATM. Both empirical evaluation and theoretical analysis are reported to verify the effectiveness of the proposed method. The experimental results on four benchmarks, both classical and large-scale, show that our method is able to achieve new state-of-the-art performance on most evaluations. Codes and datasets used in this paper are available at {\it github.com/lijin118/ATM}.
Locality Preserving Joint Transfer for Domain Adaptation
Jun 18, 2019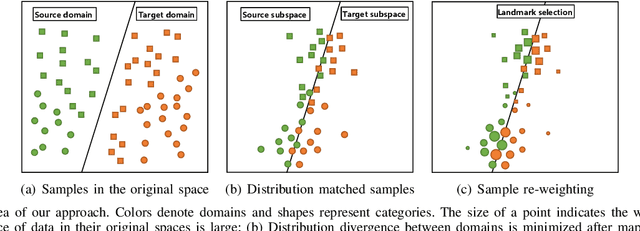
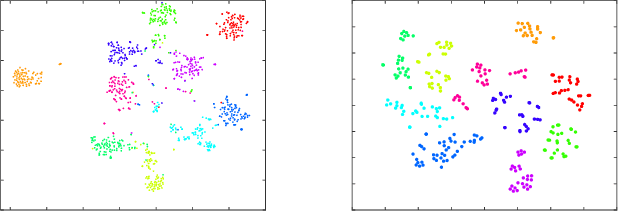

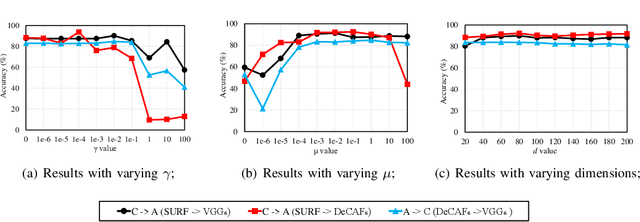
Domain adaptation aims to leverage knowledge from a well-labeled source domain to a poorly-labeled target domain. A majority of existing works transfer the knowledge at either feature level or sample level. Recent researches reveal that both of the paradigms are essentially important, and optimizing one of them can reinforce the other. Inspired by this, we propose a novel approach to jointly exploit feature adaptation with distribution matching and sample adaptation with landmark selection. During the knowledge transfer, we also take the local consistency between samples into consideration, so that the manifold structures of samples can be preserved. At last, we deploy label propagation to predict the categories of new instances. Notably, our approach is suitable for both homogeneous and heterogeneous domain adaptation by learning domain-specific projections. Extensive experiments on five open benchmarks, which consist of both standard and large-scale datasets, verify that our approach can significantly outperform not only conventional approaches but also end-to-end deep models. The experiments also demonstrate that we can leverage handcrafted features to promote the accuracy on deep features by heterogeneous adaptation.