 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Ratio-Based Trust Regions for Policy Optimization in Multi-Agent Reinforcement Learning
May 09, 2026Centralized training with decentralized execution (CTDE) is a standard framework for cooperative multi-agent policy-gradient reinforcement learning, allowing agents to learn from joint information while acting from local observations. Ratio-based trust-region methods such as Multi-Agent Proximal Policy Optimization (MAPPO) and Multi-Agent Simple Policy Optimization (MASPO) update decentralized actors using per-agent probability ratios weighted by joint advantage estimates. Teammate non-stationarity increases the variance of these advantages, which in turn increases the variance in the local ratio updates. This exposes two method-specific failure modes: MAPPO's additive clipping removes gradients for outlier samples and weakens recovery from policy drift, while MASPO's soft quadratic penalty can allow probability collapse. We introduce Multi-Agent Ratio Symmetry (MARS), a novel policy optimization objective that replaces these additive ratio-based trust-region mechanisms with a multiplicatively symmetric geometric barrier. MARS preserves corrective gradients while assigning unbounded cost as probability ratios approach zero. Across 47 tasks spanning eight multi-agent environments, including novel JAX benchmarks PaxMen and AeroJAX, MARS matches or exceeds MAPPO and MASPO in aggregate environment-level performance. Ablations show that these gains arise from the geometry of the symmetric barrier rather than from flexible trust-region boundaries alone.
Encoding Agent Trajectories as Representations with Sequence Transformers
Oct 11, 2024Spatiotemporal data faces many analogous challenges to natural language text including the ordering of locations (words) in a sequence, long range dependencies between locations, and locations having multiple meanings. In this work, we propose a novel model for representing high dimensional spatiotemporal trajectories as sequences of discrete locations and encoding them with a Transformer-based neural network architecture. Similar to language models, our Sequence Transformer for Agent Representation Encodings (STARE) model can learn representations and structure in trajectory data through both supervisory tasks (e.g., classification), and self-supervisory tasks (e.g., masked modelling). We present experimental results on various synthetic and real trajectory datasets and show that our proposed model can learn meaningful encodings that are useful for many downstream tasks including discriminating between labels and indicating similarity between locations. Using these encodings, we also learn relationships between agents and locations present in spatiotemporal data.
Fine-grained Activities of People Worldwide
Jul 11, 2022
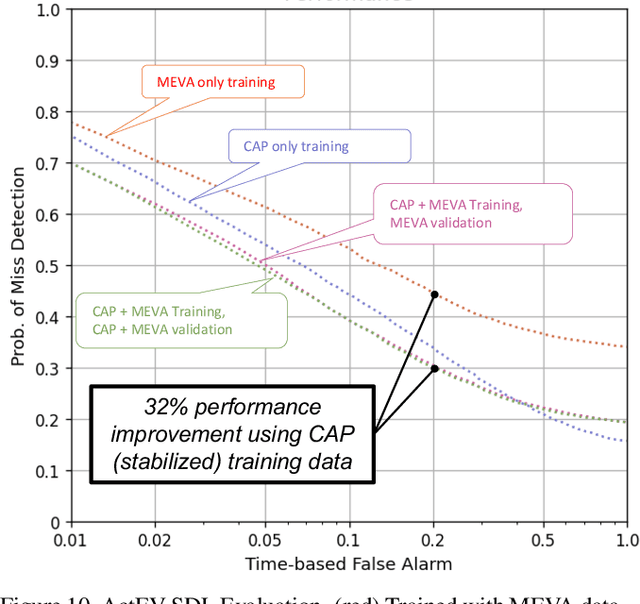
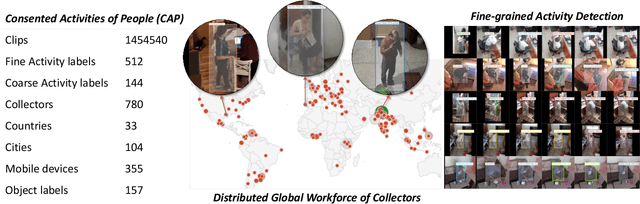
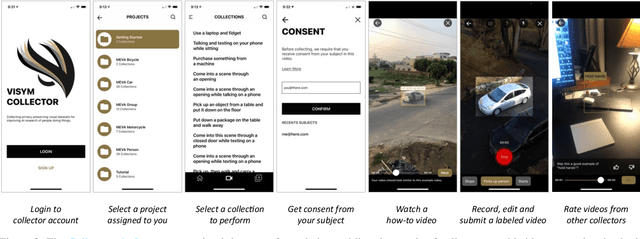
Every day, humans perform many closely related activities that involve subtle discriminative motions, such as putting on a shirt vs. putting on a jacket, or shaking hands vs. giving a high five. Activity recognition by ethical visual AI could provide insights into our patterns of daily life, however existing activity recognition datasets do not capture the massive diversity of these human activities around the world. To address this limitation, we introduce Collector, a free mobile app to record video while simultaneously annotating objects and activities of consented subjects. This new data collection platform was used to curate the Consented Activities of People (CAP) dataset, the first large-scale, fine-grained activity dataset of people worldwide. The CAP dataset contains 1.45M video clips of 512 fine grained activity labels of daily life, collected by 780 subjects in 33 countries. We provide activity classification and activity detection benchmarks for this dataset, and analyze baseline results to gain insight into how people around with world perform common activities. The dataset, benchmarks, evaluation tools, public leaderboards and mobile apps are available for use at visym.github.io/cap.
Feature Learning Viewpoint of AdaBoost and a New Algorithm
Apr 08, 2019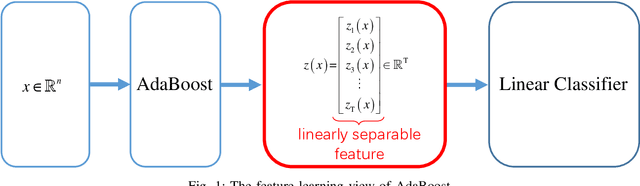
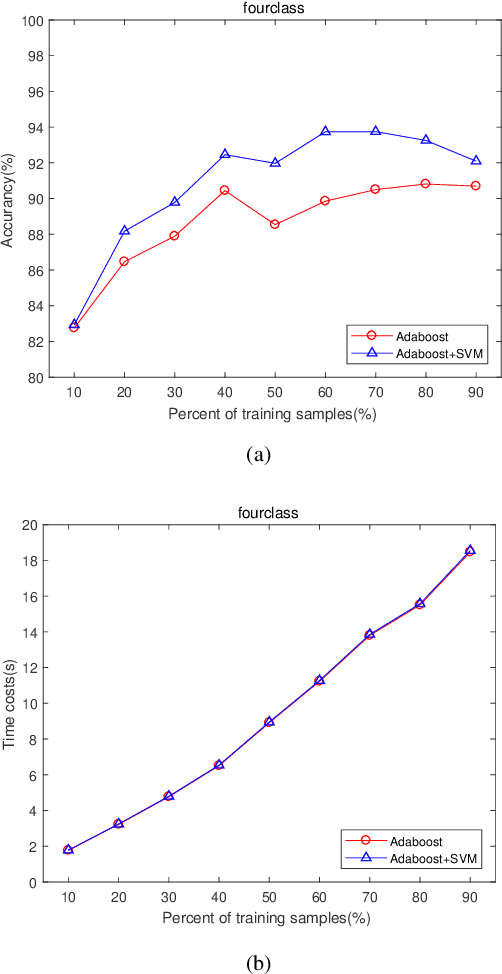
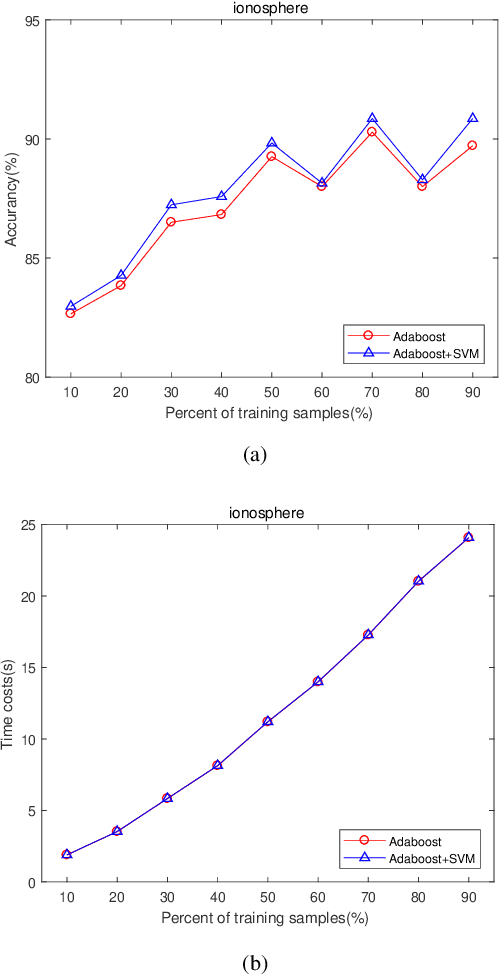
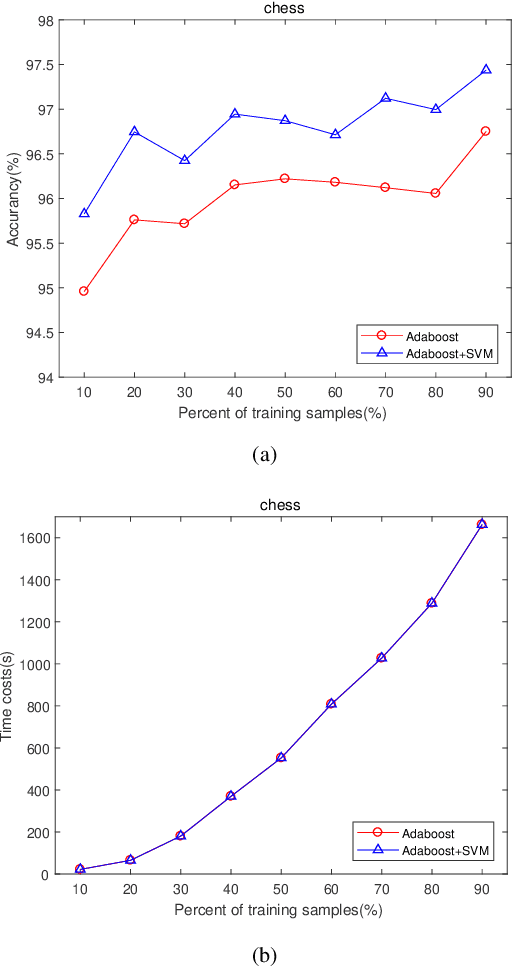
The AdaBoost algorithm has the superiority of resisting overfitting. Understanding the mysteries of this phenomena is a very fascinating fundamental theoretical problem. Many studies are devoted to explaining it from statistical view and margin theory. In this paper, we illustrate it from feature learning viewpoint, and propose the AdaBoost+SVM algorithm, which can explain the resistant to overfitting of AdaBoost directly and easily to understand. Firstly, we adopt the AdaBoost algorithm to learn the base classifiers. Then, instead of directly weighted combination the base classifiers, we regard them as features and input them to SVM classifier. With this, the new coefficient and bias can be obtained, which can be used to construct the final classifier. We explain the rationality of this and illustrate the theorem that when the dimension of these features increases, the performance of SVM would not be worse, which can explain the resistant to overfitting of AdaBoost.