 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally-Grounded Dual-Path Attention Intervention for Object Hallucination Mitigation in LVLMs
Nov 12, 2025Object hallucination remains a critical challenge in Large Vision-Language Models (LVLMs), where models generate content inconsistent with visual inputs. Existing language-decoder based mitigation approaches often regulate visual or textual attention independently, overlooking their interaction as two key causal factors. To address this, we propose Owl (Bi-mOdal attention reWeighting for Layer-wise hallucination mitigation), a causally-grounded framework that models hallucination process via a structural causal graph, treating decomposed visual and textual attentions as mediators. We introduce VTACR (Visual-to-Textual Attention Contribution Ratio), a novel metric that quantifies the modality contribution imbalance during decoding. Our analysis reveals that hallucinations frequently occur in low-VTACR scenarios, where textual priors dominate and visual grounding is weakened. To mitigate this, we design a fine-grained attention intervention mechanism that dynamically adjusts token- and layer-wise attention guided by VTACR signals. Finally, we propose a dual-path contrastive decoding strategy: one path emphasizes visually grounded predictions, while the other amplifies hallucinated ones -- letting visual truth shine and hallucination collapse. Experimental results on the POPE and CHAIR benchmarks show that Owl achieves significant hallucination reduction, setting a new SOTA in faithfulness while preserving vision-language understanding capability. Our code is available at https://github.com/CikZ2023/OWL
Is There Any Social Principle for LLM-Based Agents?
Aug 22, 2023
Focus on Large Language Model based agents should involve more than "human-centered" alignment or application. We argue that more attention should be paid to the agent itself and discuss the potential of social sciences for agents.
Shallow Network Based on Depthwise Over-Parameterized Convolution for Hyperspectral Image Classification
Dec 01, 2021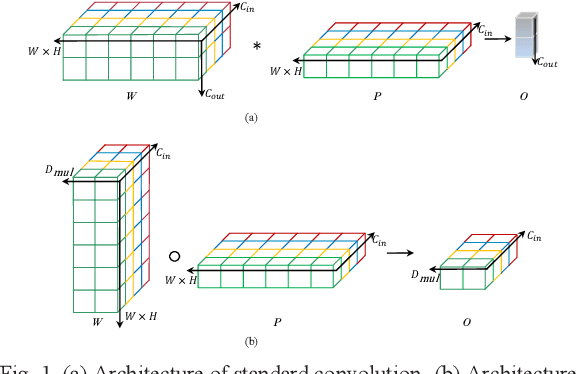
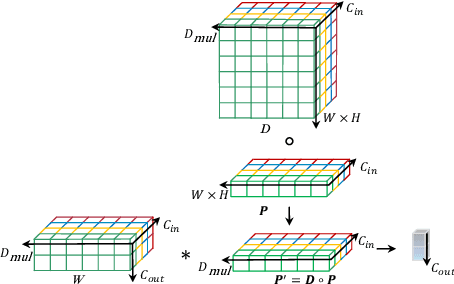
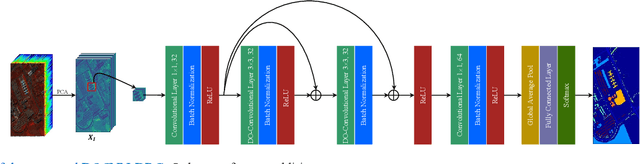
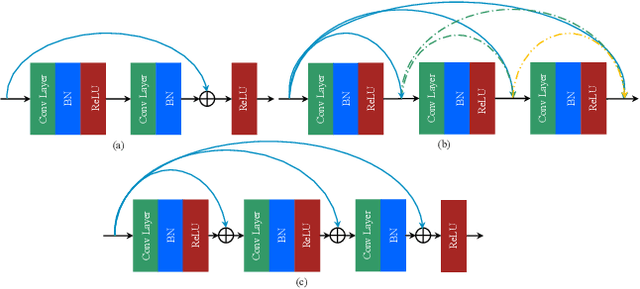
Recently, convolutional neural network (CNN) techniques have gained popularity as a tool for hyperspectral image classification (HSIC). To improve the feature extraction efficiency of HSIC under the condition of limited samples, the current methods generally use deep models with plenty of layers. However, deep network models are prone to overfitting and gradient vanishing problems when samples are limited. In addition, the spatial resolution decreases severely with deeper depth, which is very detrimental to spatial edge feature extraction. Therefore, this letter proposes a shallow model for HSIC, which is called depthwise over-parameterized convolutional neural network (DOCNN). To ensure the effective extraction of the shallow model, the depthwise over-parameterized convolution (DO-Conv) kernel is introduced to extract the discriminative features. The depthwise over-parameterized Convolution kernel is composed of a standard convolution kernel and a depthwise convolution kernel, which can extract the spatial feature of the different channels individually and fuse the spatial features of the whole channels simultaneously. Moreover, to further reduce the loss of spatial edge features due to the convolution operation, a dense residual connection (DRC) structure is proposed to apply to the feature extraction part of the whole network. Experimental results obtained from three benchmark data sets show that the proposed method outperforms other state-of-the-art methods in terms of classification accuracy and computational efficiency.