 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthTab: Leveraging Synthesized Data for Guitar Tablature Transcription
Sep 22, 2023Guitar tablature is a form of music notation widely used among guitarists. It captures not only the musical content of a piece, but also its implementation and ornamentation on the instrument. Guitar Tablature Transcription (GTT) is an important task with broad applications in music education and entertainment. Existing datasets are limited in size and scope, causing state-of-the-art GTT models trained on such datasets to suffer from overfitting and to fail in generalization across datasets. To address this issue, we developed a methodology for synthesizing SynthTab, a large-scale guitar tablature transcription dataset using multiple commercial acoustic and electric guitar plugins. This dataset is built on tablatures from DadaGP, which offers a vast collection and the degree of specificity we wish to transcribe. The proposed synthesis pipeline produces audio which faithfully adheres to the original fingerings, styles, and techniques specified in the tablature with diverse timbre. Experiments show that pre-training state-of-the-art GTT model on SynthTab improves transcription accuracy in same-dataset tests. More importantly, it significantly mitigates overfitting problems of GTT models in cross-dataset evaluation.
SingFake: Singing Voice Deepfake Detection
Sep 14, 2023The rise of singing voice synthesis presents critical challenges to artists and industry stakeholders over unauthorized voice usage. Unlike synthesized speech, synthesized singing voices are typically released in songs containing strong background music that may hide synthesis artifacts. Additionally, singing voices present different acoustic and linguistic characteristics from speech utterances. These unique properties make singing voice deepfake detection a relevant but significantly different problem from synthetic speech detection. In this work, we propose the singing voice deepfake detection task. We first present SingFake, the first curated in-the-wild dataset consisting of 28.93 hours of bonafide and 29.40 hours of deepfake song clips in five languages from 40 singers. We provide a train/val/test split where the test sets include various scenarios. We then use SingFake to evaluate four state-of-the-art speech countermeasure systems trained on speech utterances. We find these systems lag significantly behind their performance on speech test data. When trained on SingFake, either using separated vocal tracks or song mixtures, these systems show substantial improvement. However, our evaluations also identify challenges associated with unseen singers, communication codecs, languages, and musical contexts, calling for dedicated research into singing voice deepfake detection. The SingFake dataset and related resources are available online.
Mitigating Cross-Database Differences for Learning Unified HRTF Representation
Jul 27, 2023



Individualized head-related transfer functions (HRTFs) are crucial for accurate sound positioning in virtual auditory displays. As the acoustic measurement of HRTFs is resource-intensive, predicting individualized HRTFs using machine learning models is a promising approach at scale. Training such models require a unified HRTF representation across multiple databases to utilize their respectively limited samples. However, in addition to differences on the spatial sampling locations, recent studies have shown that, even for the common location, HRTFs across databases manifest consistent differences that make it trivial to tell which databases they come from. This poses a significant challenge for learning a unified HRTF representation across databases. In this work, we first identify the possible causes of these cross-database differences, attributing them to variations in the measurement setup. Then, we propose a novel approach to normalize the frequency responses of HRTFs across databases. We show that HRTFs from different databases cannot be classified by their database after normalization. We further show that these normalized HRTFs can be used to learn a more unified HRTF representation across databases than the prior art. We believe that this normalization approach paves the road to many data-intensive tasks on HRTF modeling.
Phase perturbation improves channel robustness for speech spoofing countermeasures
Jun 06, 2023In this paper, we aim to address the problem of channel robustness in speech countermeasure (CM) systems, which are used to distinguish synthetic speech from human natural speech. On the basis of two hypotheses, we suggest an approach for perturbing phase information during the training of time-domain CM systems. Communication networks often employ lossy compression codec that encodes only magnitude information, therefore heavily altering phase information. Also, state-of-the-art CM systems rely on phase information to identify spoofed speech. Thus, we believe the information loss in the phase domain induced by lossy compression codec degrades the performance of the unseen channel. We first establish the dependence of time-domain CM systems on phase information by perturbing phase in evaluation, showing strong degradation. Then, we demonstrated that perturbing phase during training leads to a significant performance improvement, whereas perturbing magnitude leads to further degradation.
SingNet: A Real-time Singing Voice Beat and Downbeat Tracking System
Jun 04, 2023



Singing voice beat and downbeat tracking posses several applications in automatic music production, analysis and manipulation. Among them, some require real-time processing, such as live performance processing and auto-accompaniment for singing inputs. This task is challenging owing to the non-trivial rhythmic and harmonic patterns in singing signals. For real-time processing, it introduces further constraints such as inaccessibility to future data and the impossibility to correct the previous results that are inconsistent with the latter ones. In this paper, we introduce the first system that tracks the beats and downbeats of singing voices in real-time. Specifically, we propose a novel dynamic particle filtering approach that incorporates offline historical data to correct the online inference by using a variable number of particles. We evaluate the performance on two datasets: GTZAN with the separated vocal tracks, and an in-house dataset with the original vocal stems. Experimental result demonstrates that our proposed approach outperforms the baseline by 3-5%.
Transcription free filler word detection with Neural semi-CRFs
Mar 11, 2023


Non-linguistic filler words, such as "uh" or "um", are prevalent in spontaneous speech and serve as indicators for expressing hesitation or uncertainty. Previous works for detecting certain non-linguistic filler words are highly dependent on transcriptions from a well-established commercial automatic speech recognition (ASR) system. However, certain ASR systems are not universally accessible from many aspects, e.g., budget, target languages, and computational power. In this work, we investigate filler word detection system that does not depend on ASR systems. We show that, by using the structured state space sequence model (S4) and neural semi-Markov conditional random fields (semi-CRFs), we achieve an absolute F1 improvement of 6.4% (segment level) and 3.1% (event level) on the PodcastFillers dataset. We also conduct a qualitative analysis on the detected results to analyze the limitations of our proposed system.
SAMO: Speaker Attractor Multi-Center One-Class Learning for Voice Anti-Spoofing
Nov 04, 2022Voice anti-spoofing systems are crucial auxiliaries for automatic speaker verification (ASV) systems. A major challenge is caused by unseen attacks empowered by advanced speech synthesis technologies. Our previous research on one-class learning has improved the generalization ability to unseen attacks by compacting the bona fide speech in the embedding space. However, such compactness lacks consideration of the diversity of speakers. In this work, we propose speaker attractor multi-center one-class learning (SAMO), which clusters bona fide speech around a number of speaker attractors and pushes away spoofing attacks from all the attractors in a high-dimensional embedding space. For training, we propose an algorithm for the co-optimization of bona fide speech clustering and bona fide/spoof classification. For inference, we propose strategies to enable anti-spoofing for speakers without enrollment. Our proposed system outperforms existing state-of-the-art single systems with a relative improvement of 38% on equal error rate (EER) on the ASVspoof2019 LA evaluation set.
HRTF Field: Unifying Measured HRTF Magnitude Representation with Neural Fields
Oct 30, 2022Head-related transfer functions (HRTFs) are a set of functions describing the spatial filtering effect of the outer ear (i.e., torso, head, and pinnae) onto sound sources at different azimuth and elevation angles. They are widely used in spatial audio rendering. While the azimuth and elevation angles are intrinsically continuous, measured HRTFs in existing datasets employ different spatial sampling schemes, making it difficult to model HRTFs across datasets. In this work, we propose to use neural fields, a differentiable representation of functions through neural networks, to model HRTFs with arbitrary spatial sampling schemes. Such representation is unified across datasets with different spatial sampling schemes. HRTFs for arbitrary azimuth and elevation angles can be derived from this representation. We further introduce a generative model named HRTF field to learn the latent space of the HRTF neural fields across subjects. We demonstrate promising performance on HRTF interpolation and generation tasks and point out potential future work.
ControlVC: Zero-Shot Voice Conversion with Time-Varying Controls on Pitch and Rhythm
Sep 23, 2022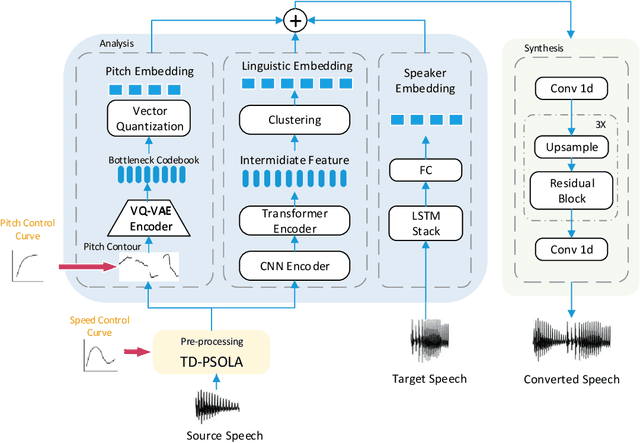
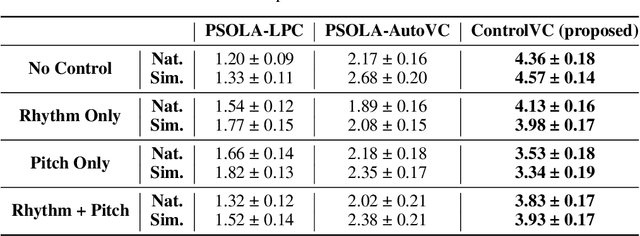
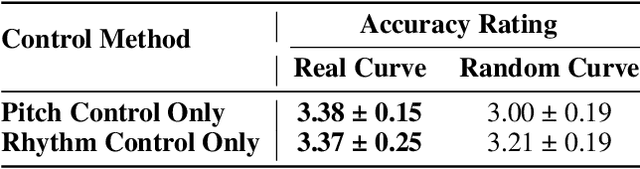
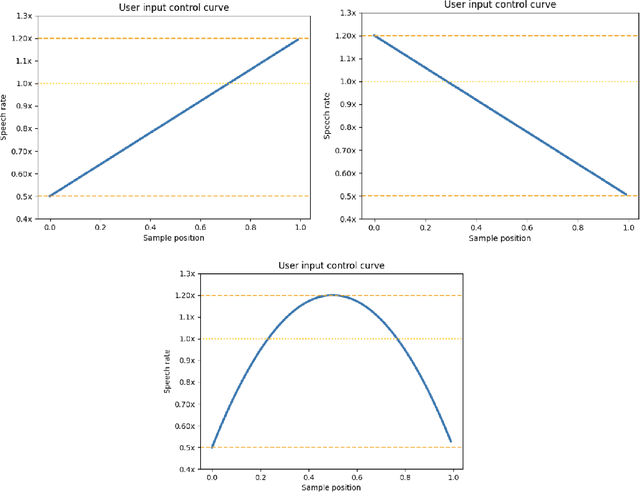
Recent developments in neural speech synthesis and vocoding have sparked a renewed interest in voice conversion (VC). Beyond timbre transfer, achieving controllability on para-linguistic parameters such as pitch and rhythm is critical in deploying VC systems in many application scenarios. Existing studies, however, either only provide utterance-level global control or lack interpretability on the controls. In this paper, we propose ControlVC, the first neural voice conversion system that achieves time-varying controls on pitch and rhythm. ControlVC uses pre-trained encoders to compute pitch embeddings and linguistic embeddings from the source utterance and speaker embeddings from the target utterance. These embeddings are then concatenated and converted to speech using a vocoder. It achieves rhythm control through TD-PSOLA pre-processing on the source utterance, and achieves pitch control by manipulating the pitch contour before feeding it to the pitch encoder. Systematic subjective and objective evaluations are conducted to assess the speech quality and controllability. Results show that, on non-parallel and zero-shot conversion tasks, ControlVC significantly outperforms two other self-constructed baselines on speech quality, and it can successfully achieve time-varying pitch control.
Singing Beat Tracking With Self-supervised Front-end and Linear Transformers
Aug 31, 2022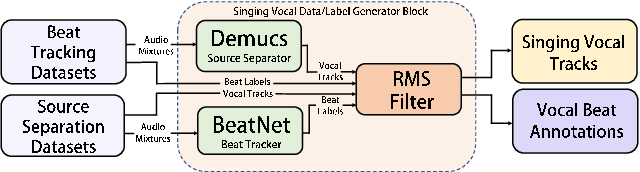
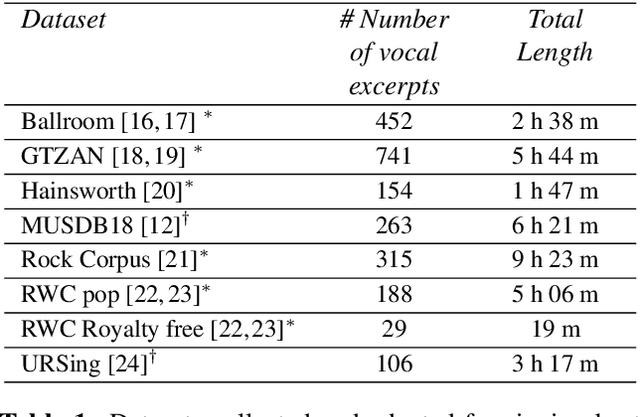

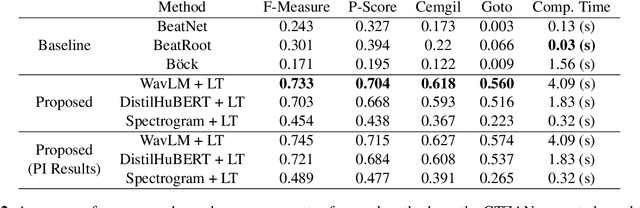
Tracking beats of singing voices without the presence of musical accompaniment can find many applications in music production, automatic song arrangement, and social media interaction. Its main challenge is the lack of strong rhythmic and harmonic patterns that are important for music rhythmic analysis in general. Even for human listeners, this can be a challenging task. As a result, existing music beat tracking systems fail to deliver satisfactory performance on singing voices. In this paper, we propose singing beat tracking as a novel task, and propose the first approach to solving this task. Our approach leverages semantic information of singing voices by employing pre-trained self-supervised WavLM and DistilHuBERT speech representations as the front-end and uses a self-attention encoder layer to predict beats. To train and test the system, we obtain separated singing voices and their beat annotations using source separation and beat tracking on complete songs, followed by manual corrections. Experiments on the 741 separated vocal tracks of the GTZAN dataset show that the proposed system outperforms several state-of-the-art music beat tracking methods by a large margin in terms of beat tracking accuracy. Ablation studies also confirm the advantages of pre-trained self-supervised speech representations over generic spectral features.