 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Motion Generation With Particle-Based Perception in Dynamic Environments
Feb 18, 2026Reactive motion generation in dynamic and unstructured scenarios is typically subject to essentially static perception and system dynamics. Reliably modeling dynamic obstacles and optimizing collision-free trajectories under perceptive and control uncertainty are challenging. This article focuses on revealing tight connection between reactive planning and dynamic mapping for manipulators from a model-based perspective. To enable efficient particle-based perception with expressively dynamic property, we present a tensorized particle weight update scheme that explicitly maintains obstacle velocities and covariance meanwhile. Building upon this dynamic representation, we propose an obstacle-aware MPPI-based planning formulation that jointly propagates robot-obstacle dynamics, allowing future system motion to be predicted and evaluated under uncertainty. The model predictive method is shown to significantly improve safety and reactivity with dynamic surroundings. By applying our complete framework in simulated and noisy real-world environments, we demonstrate that explicit modeling of robot-obstacle dynamics consistently enhances performance over state-of-the-art MPPI-based perception-planning baselines avoiding multiple static and dynamic obstacles.
Learning Multimodal Confidence for Intention Recognition in Human-Robot Interaction
May 23, 2024



The rapid development of collaborative robotics has provided a new possibility of helping the elderly who has difficulties in daily life, allowing robots to operate according to specific intentions. However, efficient human-robot cooperation requires natural, accurate and reliable intention recognition in shared environments. The current paramount challenge for this is reducing the uncertainty of multimodal fused intention to be recognized and reasoning adaptively a more reliable result despite current interactive condition. In this work we propose a novel learning-based multimodal fusion framework Batch Multimodal Confidence Learning for Opinion Pool (BMCLOP). Our approach combines Bayesian multimodal fusion method and batch confidence learning algorithm to improve accuracy, uncertainty reduction and success rate given the interactive condition. In particular, the generic and practical multimodal intention recognition framework can be easily extended further. Our desired assistive scenarios consider three modalities gestures, speech and gaze, all of which produce categorical distributions over all the finite intentions. The proposed method is validated with a six-DoF robot through extensive experiments and exhibits high performance compared to baselines.
Object Localization Assistive System Based on CV and Vibrotactile Encoding
Jun 19, 2022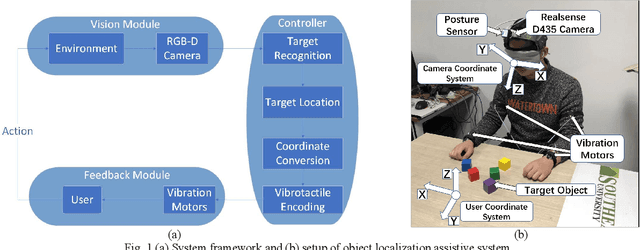
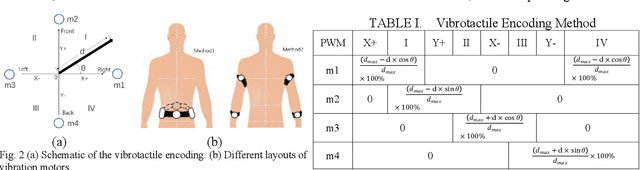
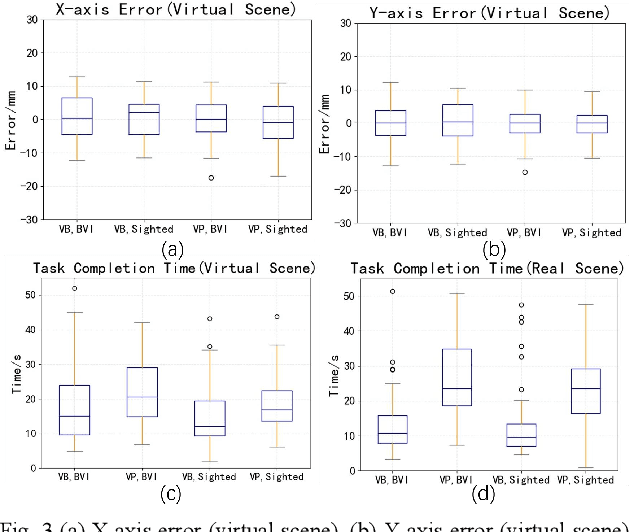
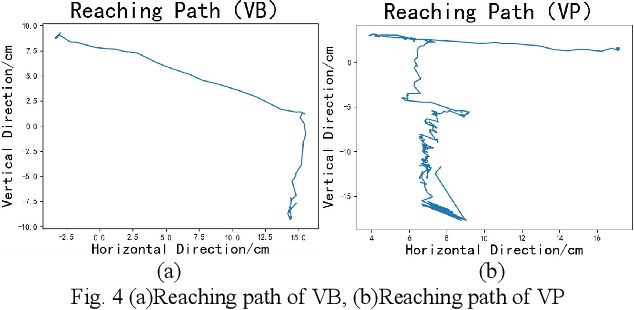
Intelligent assistive systems can navigate blind people, but most of them could only give non-intuitive cues or inefficient guidance. Based on computer vision and vibrotactile encoding, this paper presents an interactive system that provides blind people with intuitive spatial cognition. Different from the traditional auditory feedback strategy based on speech cues, this paper firstly introduces a vibration-encoded feedback method that leverages the haptic neural pathway and enables the users to interact with objects other than manipulating an assistance device. Based on this strategy, a wearable visual module based on an RGB-D camera is adopted for 3D spatial object localization, which contributes to accurate perception and quick object localization in the real environment. The experimental results on target blind individuals indicate that vibrotactile feedback reduces the task completion time by over 25% compared with the mainstream voice prompt feedback scheme. The proposed object localization system provides a more intuitive spatial navigation and comfortable wearability for blindness assistance.