 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAliyunConsoleAgent: Training Web Agents in Real-World Cloud Environments via Distillation and Reinforcement Learning
Jun 08, 2026We present AliyunConsoleAgent, a web agent framework for automated documentation verification in real-world cloud consoles. Major cloud platforms encompass hundreds of products with rapid feature iteration, causing console UIs to frequently diverge from their corresponding documentation. Verifying that documented procedures accurately reflect the current console and can be executed end-to-end demands an estimated 4 million recurring inspections annually, yet manual coverage remains below 1%. While agent systems built on frontier proprietary models achieve high success rates, their prohibitive cost and data privacy constraints preclude large-scale deployment. We propose a two-stage training paradigm: supervised fine-tuning (SFT) on distilled frontier-model trajectories, followed by reinforcement learning using Group Relative Policy Optimization (GRPO) and a dual-channel outcome reward model in real cloud environments. To support large-scale RL training, we construct a high-determinism rollout system featuring Terraform-based resource pre-provisioning and LLM-driven on-demand provisioning, which effectively isolates environment noise from the training signal. We further introduce a rule-based reward evaluation protocol grounded in backend audit logs, providing objective, reward-hacking-resistant outcome judgment. Our model evolves from mechanical instruction following to autonomous decision-making with cloud console and product-specific understanding. Experiments on a challenging 278-task benchmark where the best frontier model achieves only 65.34% demonstrate that AliyunConsoleAgent-32B achieves a 63.52% mean success rate -- a 20.24 percentage-point improvement over the base model, narrowing the gap to the best frontier proprietary model to 1.82 pp (bootstrap 95% CI [-1.27, 7.39]) -- at 92% lower inference cost.
PliableBVS: A flexible Bayesian variable selection method for modeling interactions with mandatory modifying variables
Jun 01, 2026High-dimensional interaction models are useful for studying, for example, how a large set of variables of interest, such as gene expression or other omics features, interact with a smaller set of modifying variables, such as clinical covariates. In this context, the pliable lasso has recently been proposed as an efficient method for screening large numbers of potential interaction terms under an asymmetric weak hierarchical constraint. In this work, we extend this framework by introducing PliableBVS, a Bayesian variable selection approach that preserves the hierarchical structure of the pliable lasso while inducing sparsity through spike-and-slab priors. The proposed model combines the continuous shrinkage effect of Bayesian lasso with a hierarchical spike-and-slab prior formulation that has two layers of decision variables: one governing the inclusion of main effects and another controlling the inclusion of interaction effects which is conditional on the inclusion of the corresponding main effects. This structure enables simultaneous selection of high-dimensional main and interaction effects within a coherent probabilistic framework. In simulation studies the proposed method outperforms the original pliable lasso in identifying active main and interaction effects, reducing false discoveries, and improving prediction accuracy in most scenarios. Applications with data from a labor onset study and a preeclampsia study demonstrate that PliableBVS selects biologically meaningful features and interactions.
Mixture-of-experts Wishart model for covariance matrices with an application to Cancer drug screening
Feb 14, 2026Covariance matrices arise naturally in different scientific fields, including finance, genomics, and neuroscience, where they encode dependence structures and reveal essential features of complex multivariate systems. In this work, we introduce a comprehensive Bayesian framework for analyzing heterogeneous covariance data through both classical mixture models and a novel mixture-of-experts Wishart (MoE-Wishart) model. The proposed MoE-Wishart model extends standard Wishart mixtures by allowing mixture weights to depend on predictors through a multinomial logistic gating network. This formulation enables the model to capture complex, nonlinear heterogeneity in covariance structures and to adapt subpopulation membership probabilities to covariate-dependent patterns. To perform inference, we develop an efficient Gibbs-within-Metropolis-Hastings sampling algorithm tailored to the geometry of the Wishart likelihood and the gating network. We additionally derive an Expectation-Maximization algorithm for maximum likelihood estimation in the mixture-of-experts setting. Extensive simulation studies demonstrate that the proposed Bayesian and maximum likelihood estimators achieve accurate subpopulation recovery and estimation under a range of heterogeneous covariance scenarios. Finally, we present an innovative application of our methodology to a challenging dataset: cancer drug sensitivity profiles, illustrating the ability of the MoE-Wishart model to leverage covariance across drug dosages and replicate measurements. Our methods are implemented in the \texttt{R} package \texttt{moewishart} available at https://github.com/zhizuio/moewishart .
Bayesian Cox model with graph-structured variable selection priors for multi-omics biomarker identification
Mar 17, 2025
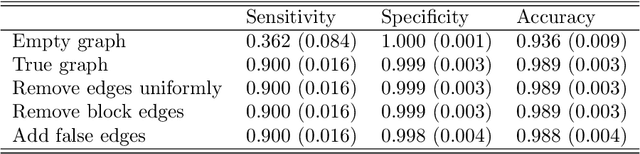
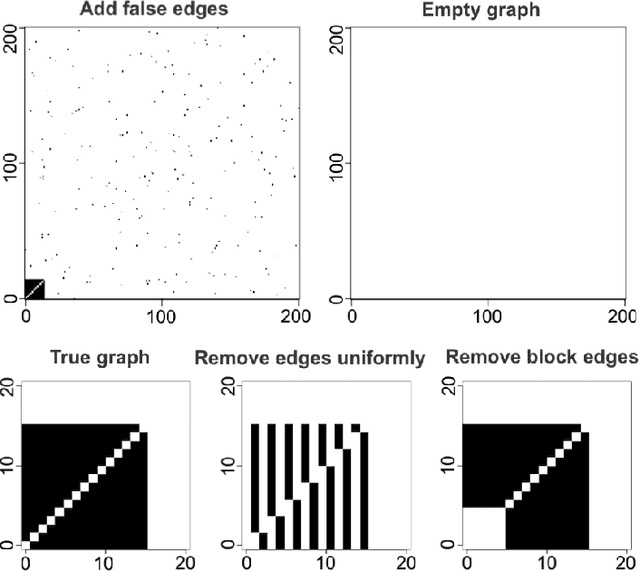
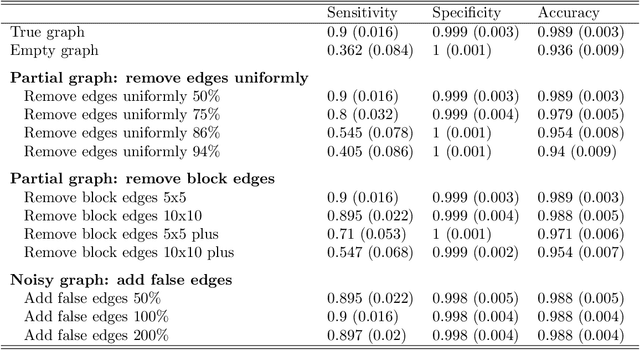
An important goal in cancer research is the survival prognosis of a patient based on a minimal panel of genomic and molecular markers such as genes or proteins. Purely data-driven models without any biological knowledge can produce non-interpretable results. We propose a penalized semiparametric Bayesian Cox model with graph-structured selection priors for sparse identification of multi-omics features by making use of a biologically meaningful graph via a Markov random field (MRF) prior to capturing known relationships between multi-omics features. Since the fixed graph in the MRF prior is for the prior probability distribution, it is not a hard constraint to determine variable selection, so the proposed model can verify known information and has the potential to identify new and novel biomarkers for drawing new biological knowledge. Our simulation results show that the proposed Bayesian Cox model with graph-based prior knowledge results in more trustable and stable variable selection and non-inferior survival prediction, compared to methods modeling the covariates independently without any prior knowledge. The results also indicate that the performance of the proposed model is robust to a partially correct graph in the MRF prior, meaning that in a real setting where not all the true network information between covariates is known, the graph can still be useful. The proposed model is applied to the primary invasive breast cancer patients data in The Cancer Genome Atlas project.