 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePliableBVS: A flexible Bayesian variable selection method for modeling interactions with mandatory modifying variables
Jun 01, 2026High-dimensional interaction models are useful for studying, for example, how a large set of variables of interest, such as gene expression or other omics features, interact with a smaller set of modifying variables, such as clinical covariates. In this context, the pliable lasso has recently been proposed as an efficient method for screening large numbers of potential interaction terms under an asymmetric weak hierarchical constraint. In this work, we extend this framework by introducing PliableBVS, a Bayesian variable selection approach that preserves the hierarchical structure of the pliable lasso while inducing sparsity through spike-and-slab priors. The proposed model combines the continuous shrinkage effect of Bayesian lasso with a hierarchical spike-and-slab prior formulation that has two layers of decision variables: one governing the inclusion of main effects and another controlling the inclusion of interaction effects which is conditional on the inclusion of the corresponding main effects. This structure enables simultaneous selection of high-dimensional main and interaction effects within a coherent probabilistic framework. In simulation studies the proposed method outperforms the original pliable lasso in identifying active main and interaction effects, reducing false discoveries, and improving prediction accuracy in most scenarios. Applications with data from a labor onset study and a preeclampsia study demonstrate that PliableBVS selects biologically meaningful features and interactions.
Bayesian Cox model with graph-structured variable selection priors for multi-omics biomarker identification
Mar 17, 2025
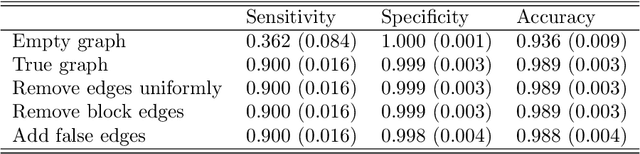
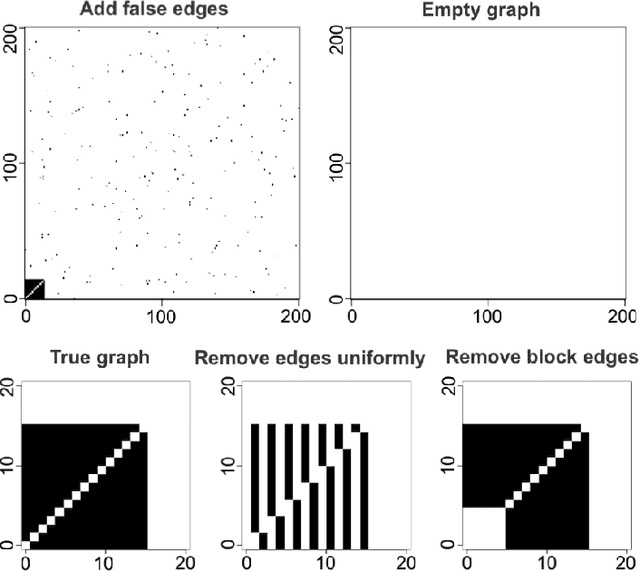
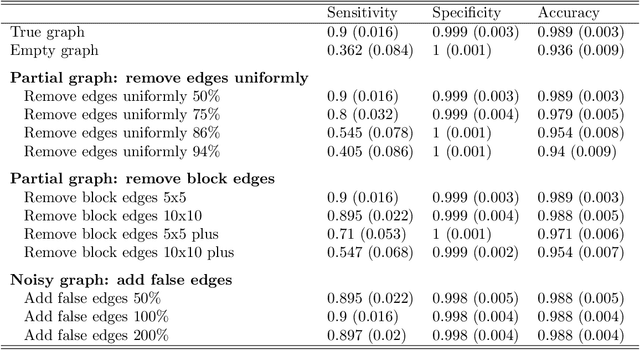
An important goal in cancer research is the survival prognosis of a patient based on a minimal panel of genomic and molecular markers such as genes or proteins. Purely data-driven models without any biological knowledge can produce non-interpretable results. We propose a penalized semiparametric Bayesian Cox model with graph-structured selection priors for sparse identification of multi-omics features by making use of a biologically meaningful graph via a Markov random field (MRF) prior to capturing known relationships between multi-omics features. Since the fixed graph in the MRF prior is for the prior probability distribution, it is not a hard constraint to determine variable selection, so the proposed model can verify known information and has the potential to identify new and novel biomarkers for drawing new biological knowledge. Our simulation results show that the proposed Bayesian Cox model with graph-based prior knowledge results in more trustable and stable variable selection and non-inferior survival prediction, compared to methods modeling the covariates independently without any prior knowledge. The results also indicate that the performance of the proposed model is robust to a partially correct graph in the MRF prior, meaning that in a real setting where not all the true network information between covariates is known, the graph can still be useful. The proposed model is applied to the primary invasive breast cancer patients data in The Cancer Genome Atlas project.
An ADMM approach for multi-response regression with overlapping groups and interaction effects
Mar 20, 2023In this paper, we consider the regularized multi-response regression problem where there exists some structural relation within the responses and also between the covariates and a set of modifying variables. To handle this problem, we propose MADMMplasso, a novel regularized regression method. This method is able to find covariates and their corresponding interactions, with some joint association with multiple related responses. We allow the interaction term between covariate and modifying variable to be included in a (weak) asymmetrical hierarchical manner by first considering whether the corresponding covariate main term is in the model. For parameter estimation, we develop an ADMM algorithm that allows us to implement the overlapping groups in a simple way. The results from the simulations and analysis of a pharmacogenomic screen data set show that the proposed method has an advantage in handling correlated responses and interaction effects, both with respect to prediction and variable selection performance.