 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Comparison Network for Remote Sensing Scene Classification
May 21, 2022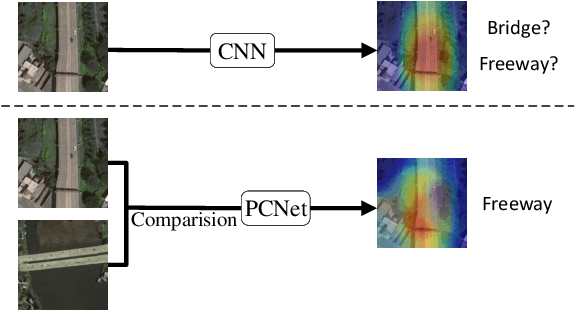
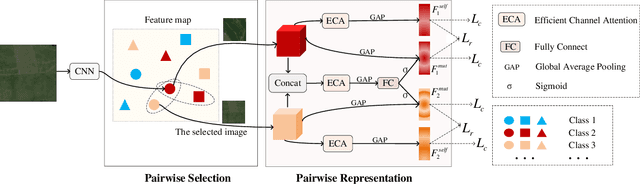
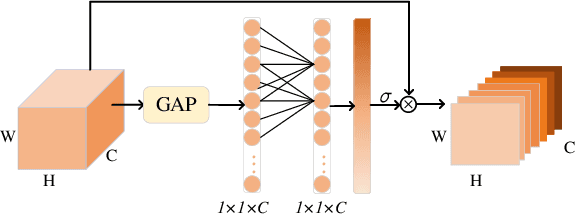
Remote sensing scene classification aims to assign a specific semantic label to a remote sensing image. Recently, convolutional neural networks have greatly improved the performance of remote sensing scene classification. However, some confused images may be easily recognized as the incorrect category, which generally degrade the performance. The differences between image pairs can be used to distinguish image categories. This paper proposed a pairwise comparison network, which contains two main steps: pairwise selection and pairwise representation. The proposed network first selects similar image pairs, and then represents the image pairs with pairwise representations. The self-representation is introduced to highlight the informative parts of each image itself, while the mutual-representation is proposed to capture the subtle differences between image pairs. Comprehensive experimental results on two challenging datasets (AID, NWPU-RESISC45) demonstrate the effectiveness of the proposed network. The codes are provided in https://github.com/spectralpublic/PCNet.git.
* 6 pages, 4 figures, published to GRSL
Cross-Lingual Dependency Parsing Using Code-Mixed TreeBank
Sep 05, 2019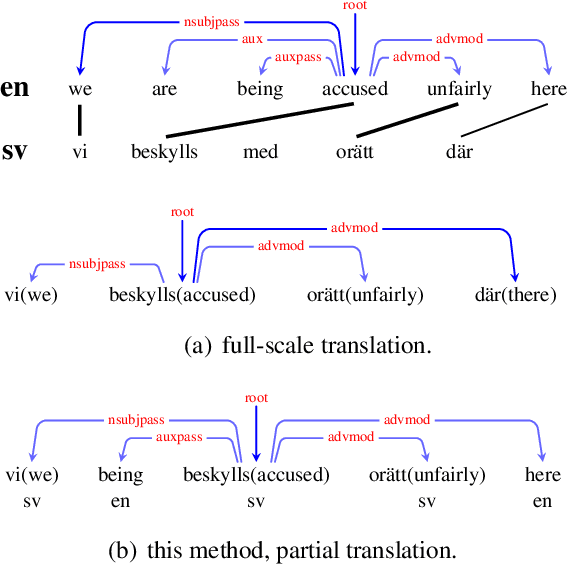
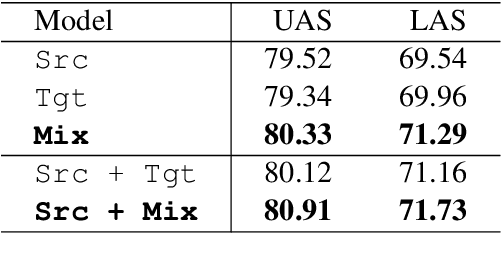
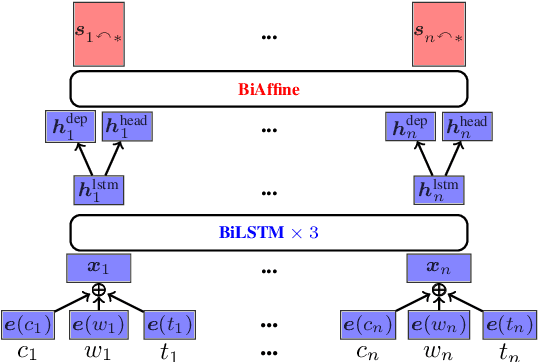
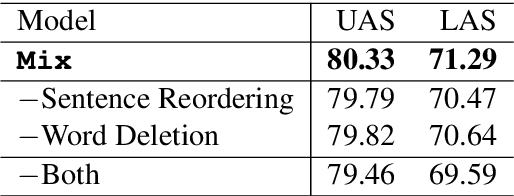
Treebank translation is a promising method for cross-lingual transfer of syntactic dependency knowledge. The basic idea is to map dependency arcs from a source treebank to its target translation according to word alignments. This method, however, can suffer from imperfect alignment between source and target words. To address this problem, we investigate syntactic transfer by code mixing, translating only confident words in a source treebank. Cross-lingual word embeddings are leveraged for transferring syntactic knowledge to the target from the resulting code-mixed treebank. Experiments on University Dependency Treebanks show that code-mixed treebanks are more effective than translated treebanks, giving highly competitive performances among cross-lingual parsing methods.
* 10 pages
X-LineNet: Detecting Aircraft in Remote Sensing Images by a pair of Intersecting Line Segments
Jul 29, 2019
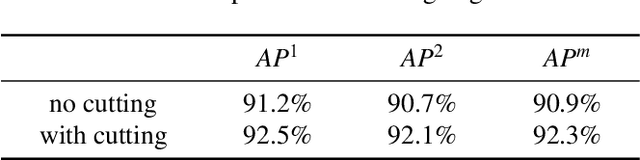
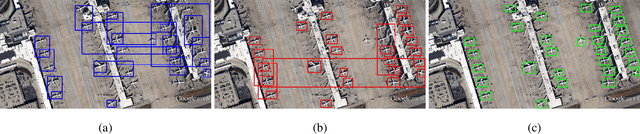
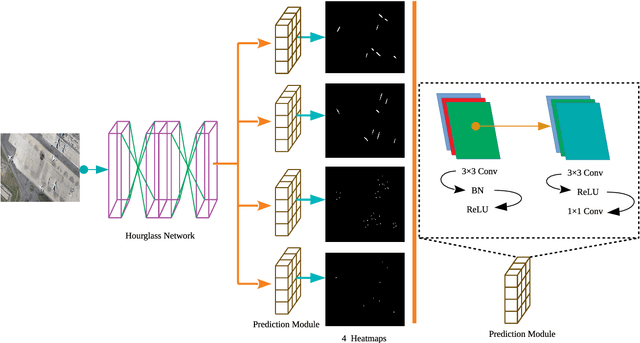
In the field of aircraft detection, tremendous progress has been gained movitated by the development of deep convolution neural networks(DCNNs). At present, most state-of-art models based on DCNNs belong to top-down approaches which take a wide use of anchor mechanism. The obtaining of high accuracy in them relys on the enumeration of massive potentional locations of objects with the form of rectangular bounding box, which is wasteful and less elaborate. In this paper, we present a novel aircraft detection model in a bottom-up manner, which formulated the task as detection of two intersecting line segments inside each target and grouping of them, thus we name it as X-LineNet. As the result of learning more delicate visual grammars information of aircraft, detection results with more concrete details and higher accuracy can be gained by X-LineNet. Just for these advantages, we designed a novel form of detetction results--pentagonal mask which has less redundancy and can better represent airplanes than that of rectangular box in remote sensing images.