 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Aware Code Generation with LLMs: Benchmarking Small vs. Large Language Models for Sustainable AI Programming
Aug 10, 2025



Large Language Models (LLMs) are widely used for code generation. However, commercial models like ChatGPT require significant computing power, which leads to high energy use and carbon emissions. This has raised concerns about their environmental impact. In this study, we evaluate open-source Small Language Models (SLMs) trained explicitly for code generation and compare their performance and energy efficiency against large LLMs and efficient human-written Python code. The goal is to investigate whether SLMs can match the performance of LLMs on certain types of programming problems while producing more energy-efficient code. We evaluate 150 coding problems from LeetCode, evenly distributed across three difficulty levels: easy, medium, and hard. Our comparison includes three small open-source models, StableCode-3B, StarCoderBase-3B, and Qwen2.5-Coder-3B-Instruct, and two large commercial models, GPT-4.0 and DeepSeek-Reasoner. The generated code is evaluated using four key metrics: run-time, memory usage, energy consumption, and correctness. We use human-written solutions as a baseline to assess the quality and efficiency of the model-generated code. Results indicate that LLMs achieve the highest correctness across all difficulty levels, but SLMs are often more energy-efficient when their outputs are correct. In over 52% of the evaluated problems, SLMs consumed the same or less energy than LLMs.
Reliability and User-Plane Latency Analysis of mmWave Massive MIMO for Grant-Free URLLC Applications
Jul 17, 2021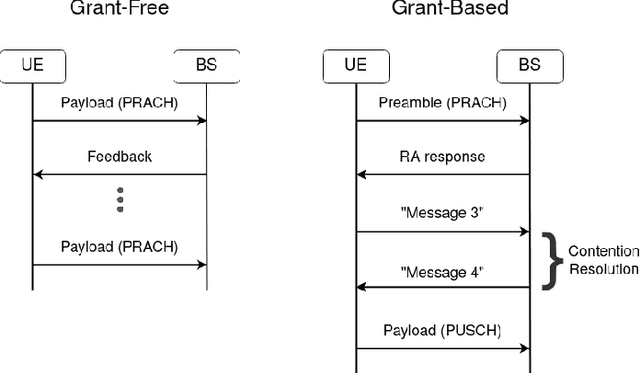
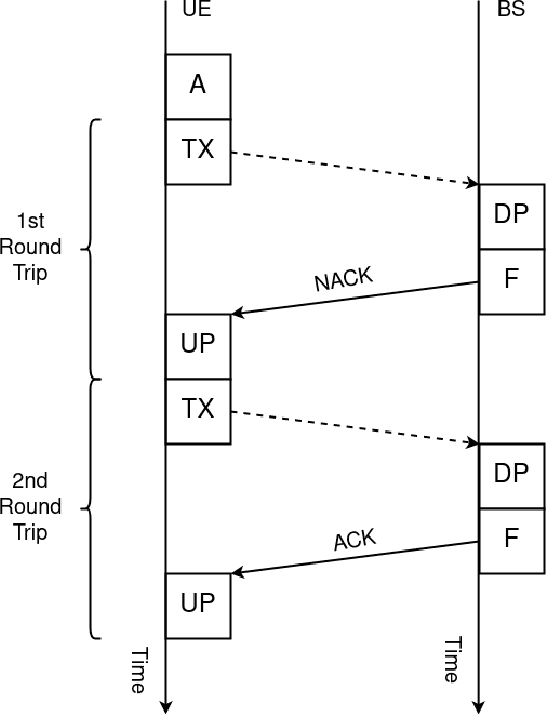
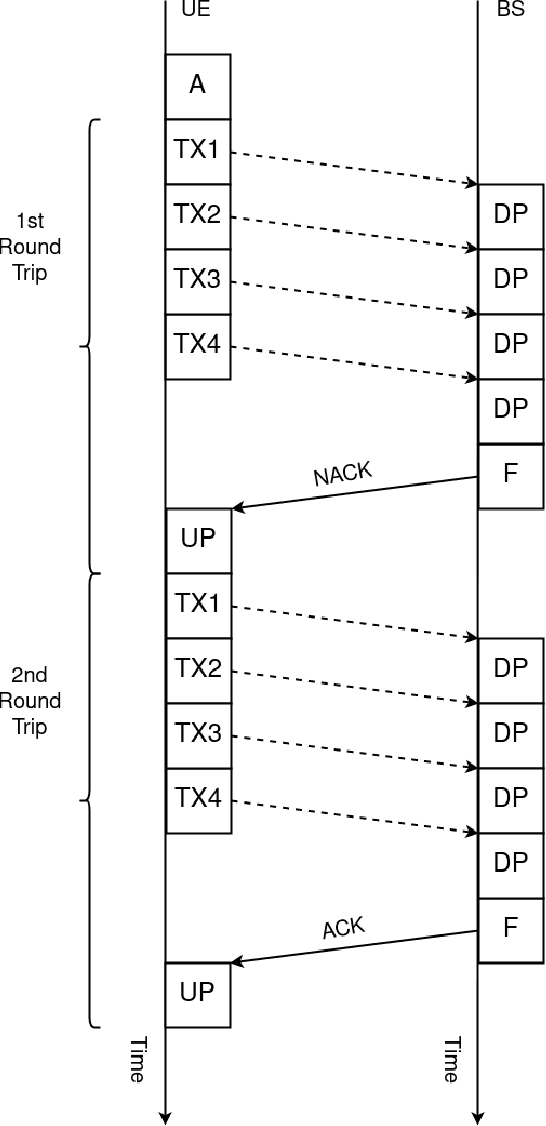
5G cellular networks are designed to support a new range of applications not supported by previous standards. Among these, ultra-reliable low-latency communication (URLLC) applications are arguably the most challenging. URLLC service requires the user equipment (UE) to be able to transmit its data under strict latency constraints with high reliability. To address these requirements, new technologies, such as mini-slots, semi-persistent scheduling and grant-free access were introduced in 5G standards. In this work, we formulate a spatiotemporal mathematical model to evaluate the user-plane latency and reliability performance of millimetre wave (mmWave) massive multiple-input multiple-output (MIMO) URLLC with reactive and K-repetition hybrid automatic repeat request (HARQ) protocols. We derive closed-form approximate expressions for the latent access failure probability and validate them using numerical simulations. The results show that, under certain conditions, mmWave massive MIMO can reduce the failure probability by a factor of 32. Moreover, we identify that beyond a certain number of antennas there is no significant improvement in reliability. Finally, we conclude that mmWave massive MIMO alone is not enough to provide the performance guarantees required by the most stringent URLLC applications.
Intelligent Link Adaptation for Grant-Free Access Cellular Networks: A Distributed Deep Reinforcement Learning Approach
Jul 08, 2021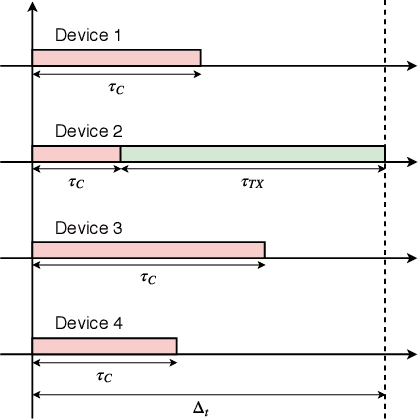
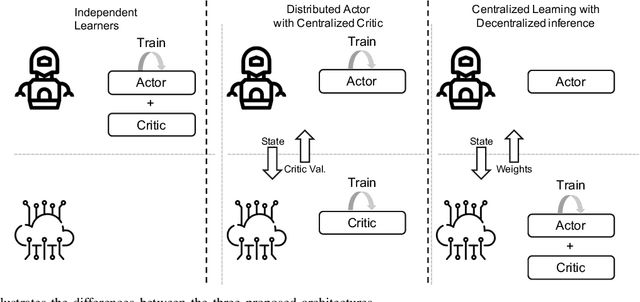
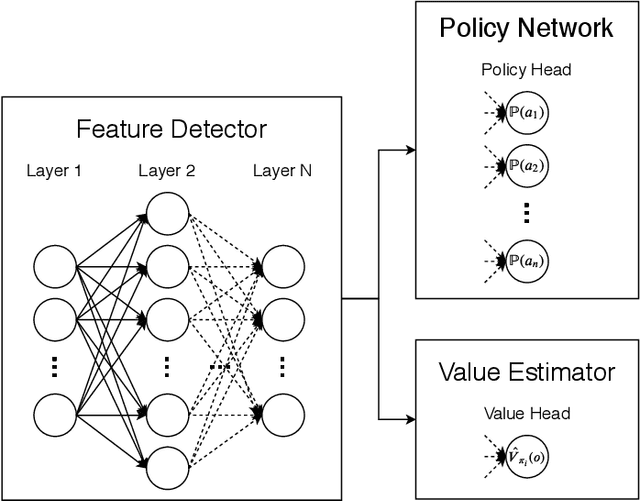
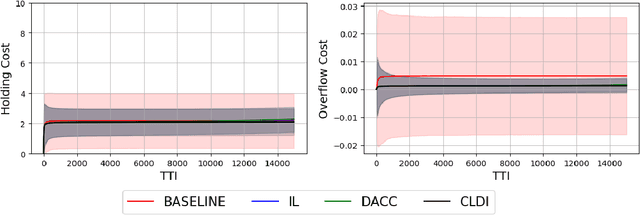
With the continuous growth of machine-type devices (MTDs), it is expected that massive machine-type communication (mMTC) will be the dominant form of traffic in future wireless networks. Applications based on this technology, have fundamentally different traffic characteristics from human-to-human (H2H) communication, which involves a relatively small number of devices transmitting large packets consistently. Conversely, in mMTC applications, a very large number of MTDs transmit small packets sporadically. Therefore, conventional grant-based access schemes commonly adopted for H2H service, are not suitable for mMTC, as they incur in a large overhead associated with the channel request procedure. We propose three grant-free distributed optimization architectures that are able to significantly minimize the average power consumption of the network. The problem of physical layer (PHY) and medium access control (MAC) optimization in grant-free random access transmission is is modeled as a partially observable stochastic game (POSG) aimed at minimizing the average transmit power under a per-device delay constraint. The results show that the proposed architectures are able to achieve significantly less average latency than a baseline, while spending less power. Moreover, the proposed architectures are more robust than the baseline, as they present less variance in the performance for different system realizations.