 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Time Series Forecasting with Anomalies
Dec 12, 2025Time series forecasting predicts future values from past data. In real-world settings, some anomalous events have lasting effects and influence the forecast, while others are short-lived and should be ignored. Standard forecasting models fail to make this distinction, often either overreacting to noise or missing persistent shifts. We propose Co-TSFA (Contrastive Time Series Forecasting with Anomalies), a regularization framework that learns when to ignore anomalies and when to respond. Co-TSFA generates input-only and input-output augmentations to model forecast-irrelevant and forecast-relevant anomalies, and introduces a latent-output alignment loss that ties representation changes to forecast changes. This encourages invariance to irrelevant perturbations while preserving sensitivity to meaningful distributional shifts. Experiments on the Traffic and Electricity benchmarks, as well as on a real-world cash-demand dataset, demonstrate that Co-TSFA improves performance under anomalous conditions while maintaining accuracy on normal data. An anonymized GitHub repository with the implementation of Co-TSFA is provided and will be made public upon acceptance.
Weighted Contrastive Learning for Anomaly-Aware Time-Series Forecasting
Dec 08, 2025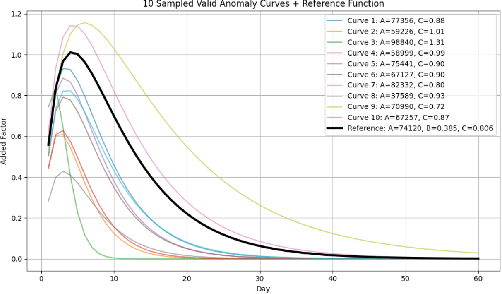
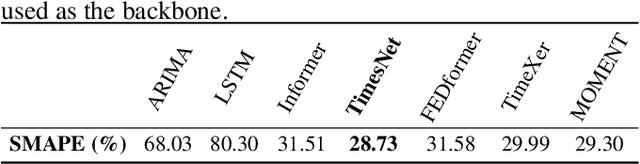
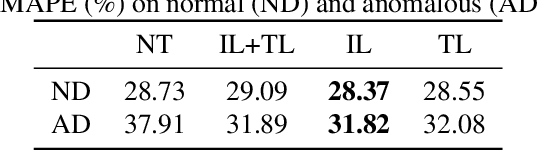
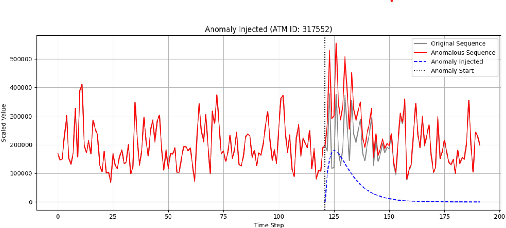
Reliable forecasting of multivariate time series under anomalous conditions is crucial in applications such as ATM cash logistics, where sudden demand shifts can disrupt operations. Modern deep forecasters achieve high accuracy on normal data but often fail when distribution shifts occur. We propose Weighted Contrastive Adaptation (WECA), a Weighted contrastive objective that aligns normal and anomaly-augmented representations, preserving anomaly-relevant information while maintaining consistency under benign variations. Evaluations on a nationwide ATM transaction dataset with domain-informed anomaly injection show that WECA improves SMAPE on anomaly-affected data by 6.1 percentage points compared to a normally trained baseline, with negligible degradation on normal data. These results demonstrate that WECA enhances forecasting reliability under anomalies without sacrificing performance during regular operations.
Heterogeneous Federated Learning via Personalized Generative Networks
Aug 25, 2023Federated Learning (FL) allows several clients to construct a common global machine-learning model without having to share their data. FL, however, faces the challenge of statistical heterogeneity between the client's data, which degrades performance and slows down the convergence toward the global model. In this paper, we provide theoretical proof that minimizing heterogeneity between clients facilitates the convergence of a global model for every single client. This becomes particularly important under empirical concept shifts among clients, rather than merely considering imbalanced classes, which have been studied until now. Therefore, we propose a method for knowledge transfer between clients where the server trains client-specific generators. Each generator generates samples for the corresponding client to remove the conflict with other clients' models. Experiments conducted on synthetic and real data, along with a theoretical study, support the effectiveness of our method in constructing a well-generalizable global model by reducing the conflict between local models.