 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Error Level Noise Embedding for Improving LLM-Assisted Robustness in Persian Speech Recognition
Dec 19, 2025Automatic Speech Recognition (ASR) systems suffer significant performance degradation in noisy environments, a challenge that is especially severe for low-resource languages such as Persian. Even state-of-the-art models such as Whisper struggle to maintain accuracy under varying signal-to-noise ratios (SNRs). This study presents a robust noise-sensitive ASR error correction framework that combines multiple hypotheses and noise-aware modeling. Using noisy Persian speech, we generate 5-best hypotheses from a modified Whisper-large decoder. Error Level Noise (ELN) is introduced as a representation that captures semantic- and token-level disagreement across hypotheses, quantifying the linguistic distortions caused by noise. ELN thus provides a direct measure of noise-induced uncertainty, enabling the LLM to reason about the reliability of each hypothesis during correction. Three models are evaluated: (1) a base LLaMA-2-7B model without fine-tuning, (2) a fine-tuned variant trained on text-only hypotheses, and (3) a noise-conditioned model integrating ELN embeddings at both sentence and word levels. Experimental results demonstrate that the ELN-conditioned model achieves substantial reductions in Word Error Rate (WER). Specifically, on the challenging Mixed Noise test set, the proposed Fine-tuned + ELN (Ours) model reduces the WER from a baseline of 31.10\% (Raw Whisper) to 24.84\%, significantly surpassing the Fine-tuned (No ELN) text-only baseline of 30.79\%, whereas the original LLaMA-2-7B model increased the WER to 64.58\%, demonstrating that it is unable to correct Persian errors on its own. This confirms the effectiveness of combining multiple hypotheses with noise-aware embeddings for robust Persian ASR in noisy real-world scenarios.
$K^4$: Online Log Anomaly Detection Via Unsupervised Typicality Learning
Jul 26, 2025



Existing Log Anomaly Detection (LogAD) methods are often slow, dependent on error-prone parsing, and use unrealistic evaluation protocols. We introduce $K^4$, an unsupervised and parser-independent framework for high-performance online detection. $K^4$ transforms arbitrary log embeddings into compact four-dimensional descriptors (Precision, Recall, Density, Coverage) using efficient k-nearest neighbor (k-NN) statistics. These descriptors enable lightweight detectors to accurately score anomalies without retraining. Using a more realistic online evaluation protocol, $K^4$ sets a new state-of-the-art (AUROC: 0.995-0.999), outperforming baselines by large margins while being orders of magnitude faster, with training under 4 seconds and inference as low as 4 $\mu$s.
Real time ridge orientation estimation for fingerprint images
Oct 13, 2017

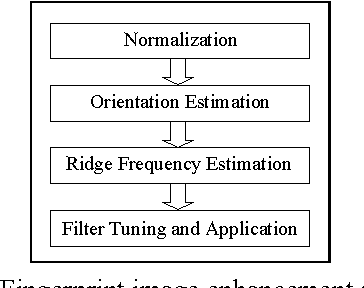

Fingerprint verification is an important bio-metric technique for personal identification. Most of the automatic verification systems are based on matching of fingerprint minutiae. Extraction of minutiae is an essential process which requires estimation of orientation of the lines in an image. Most of the existing methods involve intense mathematical computations and hence are performed through software means. In this paper a hardware scheme to perform real time orientation estimation is presented which is based on pipelined architecture. Synthesized circuits proved the functionality and accuracy of the suggested method.