 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Library Theorem: How External Organization Governs Agentic Reasoning Capacity
Mar 22, 2026Externalized reasoning is already exploited by transformer-based agents through chain-of-thought, but structured retrieval -- indexing over one's own reasoning state -- remains underexplored. We formalize the transformer context window as an I/O page and prove that tool-augmented agents with indexed external memory achieve exponentially lower retrieval cost than agents restricted to sequential scanning: $O(\log_b N)$ versus $Ω(N)$ page reads per query, and $O(T \log_b T)$ versus $Θ(T^2)$ cumulative cost over $T$ reasoning steps -- a gap that widens as deliberation deepens. We test these predictions on a controlled lookup benchmark across three content types -- random hashes, ordered integers, and encyclopedia entries -- varying store size from 50 to 5,000 items, and replicate key conditions across two model generations (GPT-4o-mini and GPT-5.4). On abstract content, the indexed agent achieves median 1 page read regardless of store size, confirming the $O(1)$ prediction. Sorted pages without an index fail to close the gap: the weaker model cannot sustain binary search at scale, and the stronger model achieves near-optimal $\log_2 N$ search but still loses to the index by $5\times$. On familiar content (encyclopedia entries), a competing failure mode emerges: the model recognizes the domain, bypasses the retrieval protocol, and generates answers from parametric memory, producing catastrophic token expenditure even when the index is sound. This parametric memory competition dissociates the two cognitive operations that indexing combines: understanding content (where language models excel) and following navigational protocols (where they fail when understanding tempts them to shortcut). The result argues for a separation of concerns: use language models for index construction, where semantic understanding helps, and deterministic algorithms for index traversal, where it hurts.
Demixed principal component analysis of population activity in higher cortical areas reveals independent representation of task parameters
Oct 22, 2014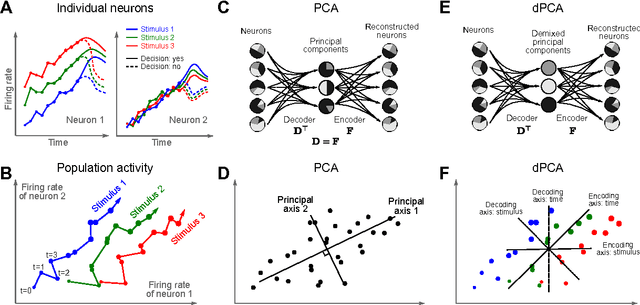
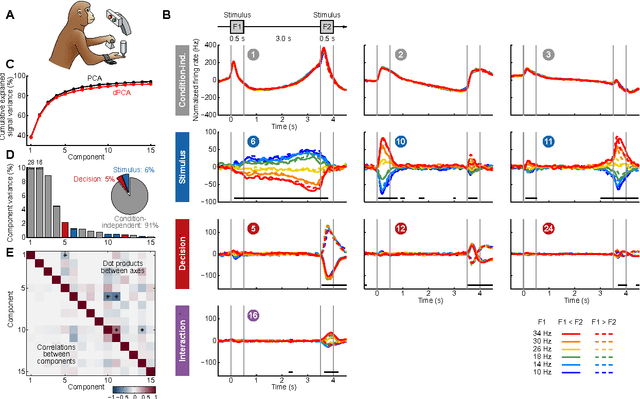
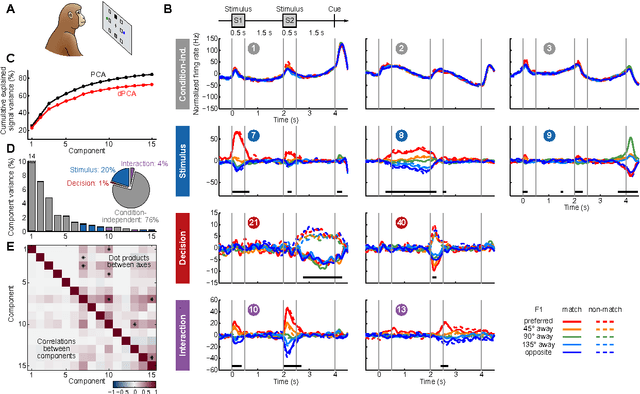
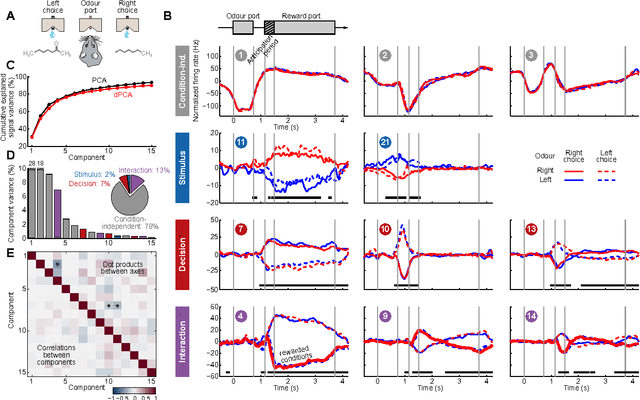
Neurons in higher cortical areas, such as the prefrontal cortex, are known to be tuned to a variety of sensory and motor variables. The resulting diversity of neural tuning often obscures the represented information. Here we introduce a novel dimensionality reduction technique, demixed principal component analysis (dPCA), which automatically discovers and highlights the essential features in complex population activities. We reanalyze population data from the prefrontal areas of rats and monkeys performing a variety of working memory and decision-making tasks. In each case, dPCA summarizes the relevant features of the population response in a single figure. The population activity is decomposed into a few demixed components that capture most of the variance in the data and that highlight dynamic tuning of the population to various task parameters, such as stimuli, decisions, rewards, etc. Moreover, dPCA reveals strong, condition-independent components of the population activity that remain unnoticed with conventional approaches.