 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Descriptors: Convolutional Maps for Preprocessing
May 10, 2017

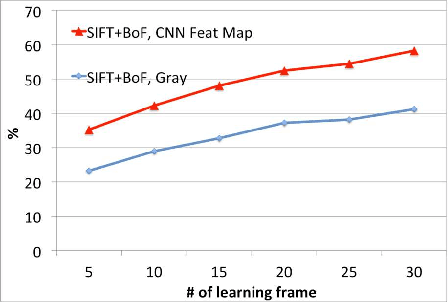
The paper presents a novel concept for collaborative descriptors between deeply learned and hand-crafted features. To achieve this concept, we apply convolutional maps for pre-processing, namely the convovlutional maps are used as input of hand-crafted features. We recorded an increase in the performance rate of +17.06 % (multi-class object recognition) and +24.71 % (car detection) from grayscale input to convolutional maps. Although the framework is straight-forward, the concept should be inherited for an improved representation.
Changing Fashion Cultures
Mar 23, 2017

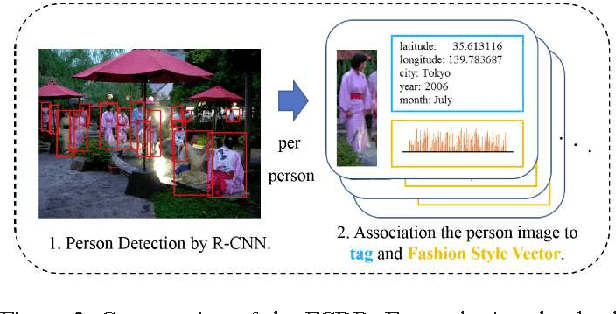
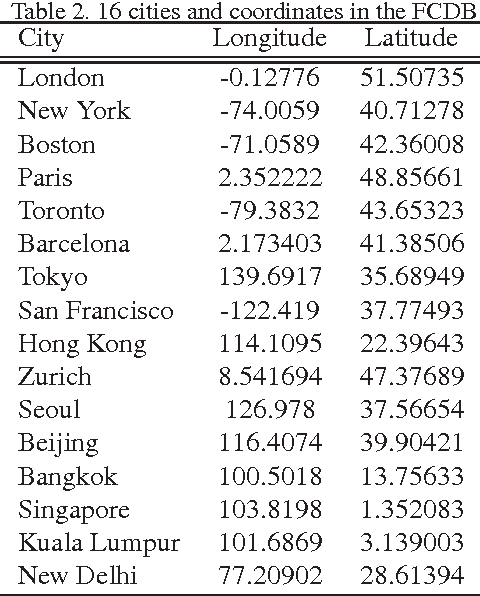
The paper presents a novel concept that analyzes and visualizes worldwide fashion trends. Our goal is to reveal cutting-edge fashion trends without displaying an ordinary fashion style. To achieve the fashion-based analysis, we created a new fashion culture database (FCDB), which consists of 76 million geo-tagged images in 16 cosmopolitan cities. By grasping a fashion trend of mixed fashion styles,the paper also proposes an unsupervised fashion trend descriptor (FTD) using a fashion descriptor, a codeword vetor, and temporal analysis. To unveil fashion trends in the FCDB, the temporal analysis in FTD effectively emphasizes consecutive features between two different times. In experiments, we clearly show the analysis of fashion trends and fashion-based city similarity. As the result of large-scale data collection and an unsupervised analyzer, the proposed approach achieves world-level fashion visualization in a time series. The code, model, and FCDB will be publicly available after the construction of the project page.
Semantic Change Detection with Hypermaps
Mar 16, 2017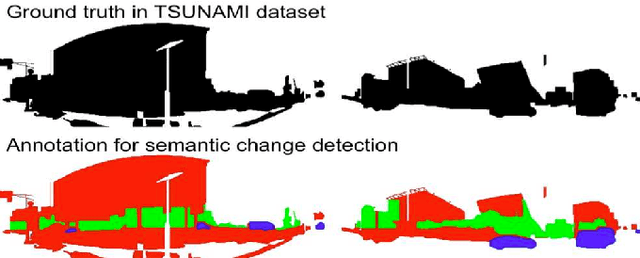
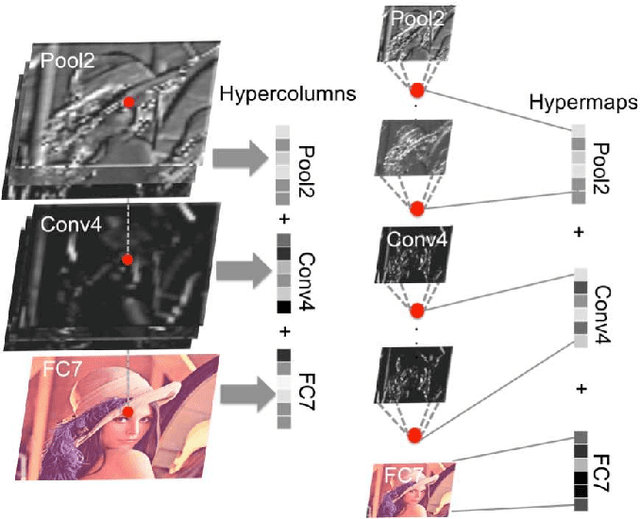

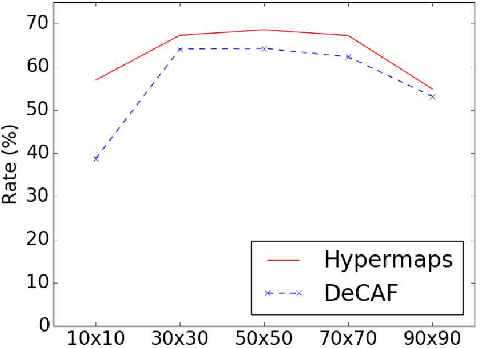
Change detection is the study of detecting changes between two different images of a scene taken at different times. By the detected change areas, however, a human cannot understand how different the two images. Therefore, a semantic understanding is required in the change detection research such as disaster investigation. The paper proposes the concept of semantic change detection, which involves intuitively inserting semantic meaning into detected change areas. We mainly focus on the novel semantic segmentation in addition to a conventional change detection approach. In order to solve this problem and obtain a high-level of performance, we propose an improvement to the hypercolumns representation, hereafter known as hypermaps, which effectively uses convolutional maps obtained from convolutional neural networks (CNNs). We also employ multi-scale feature representation captured by different image patches. We applied our method to the TSUNAMI Panoramic Change Detection dataset, and re-annotated the changed areas of the dataset via semantic classes. The results show that our multi-scale hypermaps provided outstanding performance on the re-annotated TSUNAMI dataset.
Motion Representation with Acceleration Images
Aug 30, 2016
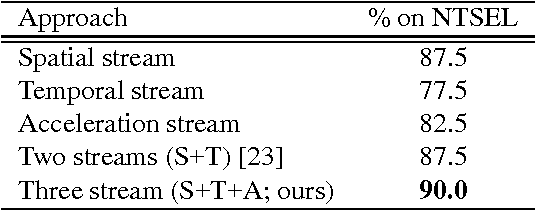

Information of time differentiation is extremely important cue for a motion representation. We have applied first-order differential velocity from a positional information, moreover we believe that second-order differential acceleration is also a significant feature in a motion representation. However, an acceleration image based on a typical optical flow includes motion noises. We have not employed the acceleration image because the noises are too strong to catch an effective motion feature in an image sequence. On one hand, the recent convolutional neural networks (CNN) are robust against input noises. In this paper, we employ acceleration-stream in addition to the spatial- and temporal-stream based on the two-stream CNN. We clearly show the effectiveness of adding the acceleration stream to the two-stream CNN.
Human Action Recognition without Human
Aug 29, 2016

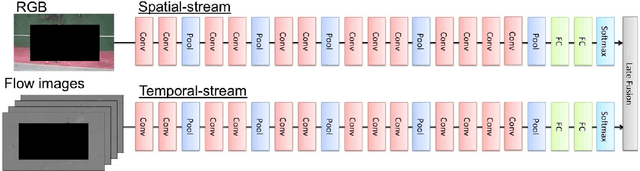
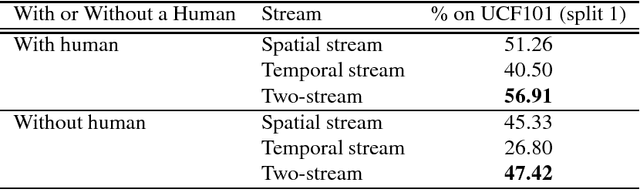
The objective of this paper is to evaluate "human action recognition without human". Motion representation is frequently discussed in human action recognition. We have examined several sophisticated options, such as dense trajectories (DT) and the two-stream convolutional neural network (CNN). However, some features from the background could be too strong, as shown in some recent studies on human action recognition. Therefore, we considered whether a background sequence alone can classify human actions in current large-scale action datasets (e.g., UCF101). In this paper, we propose a novel concept for human action analysis that is named "human action recognition without human". An experiment clearly shows the effect of a background sequence for understanding an action label.
Dominant Codewords Selection with Topic Model for Action Recognition
May 01, 2016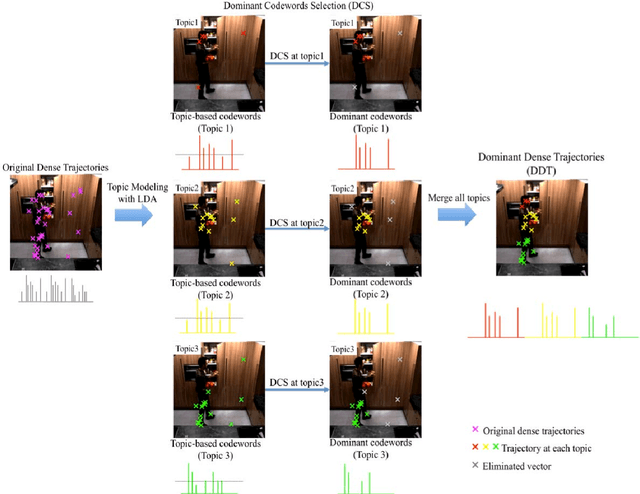
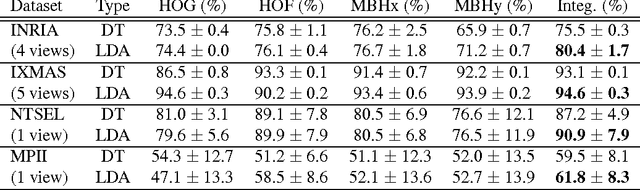

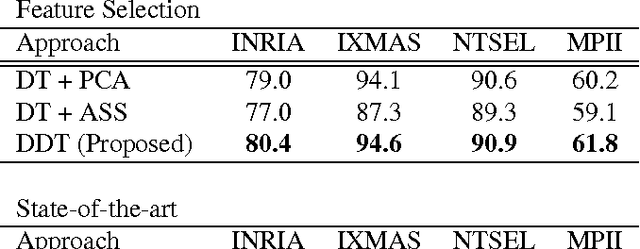
In this paper, we propose a framework for recognizing human activities that uses only in-topic dominant codewords and a mixture of intertopic vectors. Latent Dirichlet allocation (LDA) is used to develop approximations of human motion primitives; these are mid-level representations, and they adaptively integrate dominant vectors when classifying human activities. In LDA topic modeling, action videos (documents) are represented by a bag-of-words (input from a dictionary), and these are based on improved dense trajectories. The output topics correspond to human motion primitives, such as finger moving or subtle leg motion. We eliminate the impurities, such as missed tracking or changing light conditions, in each motion primitive. The assembled vector of motion primitives is an improved representation of the action. We demonstrate our method on four different datasets.
Feature Evaluation of Deep Convolutional Neural Networks for Object Recognition and Detection
Sep 25, 2015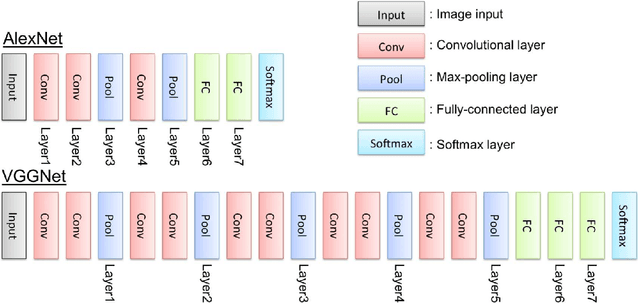

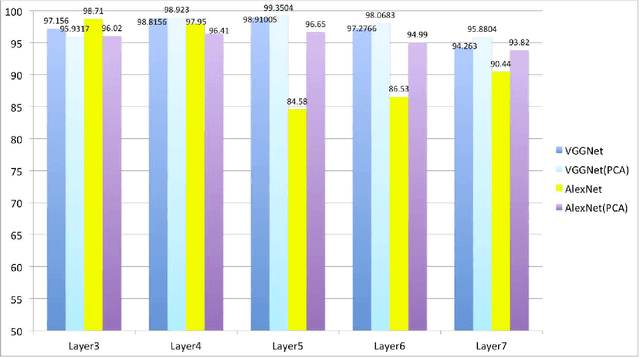

In this paper, we evaluate convolutional neural network (CNN) features using the AlexNet architecture and very deep convolutional network (VGGNet) architecture. To date, most CNN researchers have employed the last layers before output, which were extracted from the fully connected feature layers. However, since it is unlikely that feature representation effectiveness is dependent on the problem, this study evaluates additional convolutional layers that are adjacent to fully connected layers, in addition to executing simple tuning for feature concatenation (e.g., layer 3 + layer 5 + layer 7) and transformation, using tools such as principal component analysis. In our experiments, we carried out detection and classification tasks using the Caltech 101 and Daimler Pedestrian Benchmark Datasets.