 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Neural Networks++
Jun 15, 2020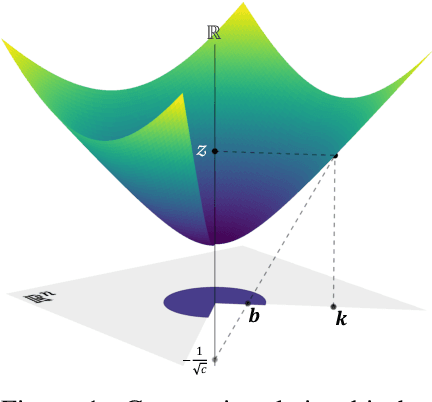
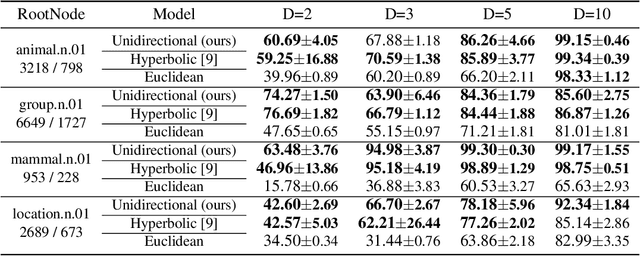
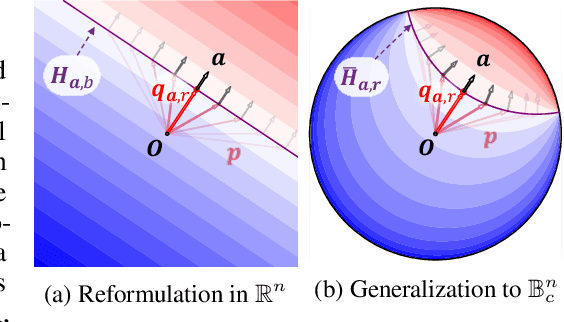

Hyperbolic spaces, which have the capacity to embed tree structures without distortion owing to their exponential volume growth, have recently been applied to machine learning to better capture the hierarchical nature of data. In this study, we reconsider a way to generalize the fundamental components of neural networks in a single hyperbolic geometry model, and propose novel methodologies to construct a multinomial logistic regression, fully-connected layers, convolutional layers, and attention mechanisms under a unified mathematical interpretation, without increasing the parameters. A series of experiments show the parameter efficiency of our methods compared to a conventional hyperbolic component, and stability and outperformance over their Euclidean counterparts.
Multi-Stage Pathological Image Classification using Semantic Segmentation
Oct 10, 2019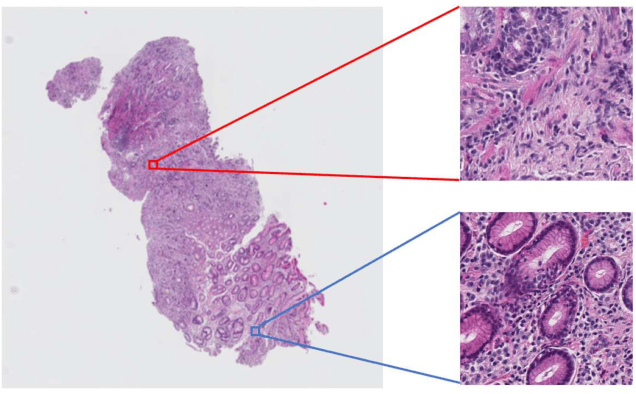
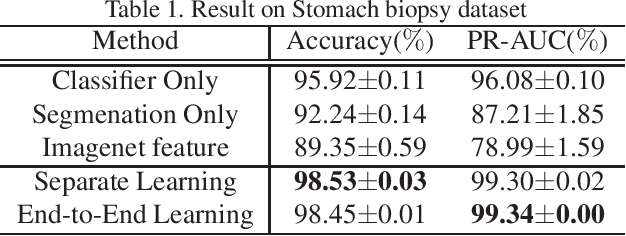
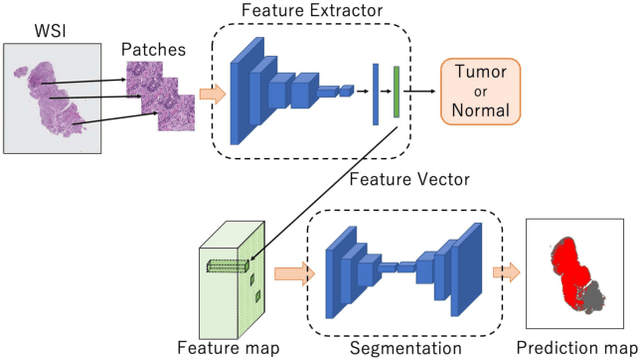
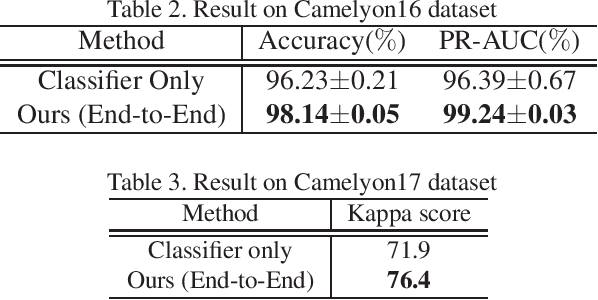
Histopathological image analysis is an essential process for the discovery of diseases such as cancer. However, it is challenging to train CNN on whole slide images (WSIs) of gigapixel resolution considering the available memory capacity. Most of the previous works divide high resolution WSIs into small image patches and separately input them into the model to classify it as a tumor or a normal tissue. However, patch-based classification uses only patch-scale local information but ignores the relationship between neighboring patches. If we consider the relationship of neighboring patches and global features, we can improve the classification performance. In this paper, we propose a new model structure combining the patch-based classification model and whole slide-scale segmentation model in order to improve the prediction performance of automatic pathological diagnosis. We extract patch features from the classification model and input them into the segmentation model to obtain a whole slide tumor probability heatmap. The classification model considers patch-scale local features, and the segmentation model can take global information into account. We also propose a new optimization method that retains gradient information and trains the model partially for end-to-end learning with limited GPU memory capacity. We apply our method to the tumor/normal prediction on WSIs and the classification performance is improved compared with the conventional patch-based method.
Rethinking Task and Metrics of Instance Segmentation on 3D Point Clouds
Sep 27, 2019

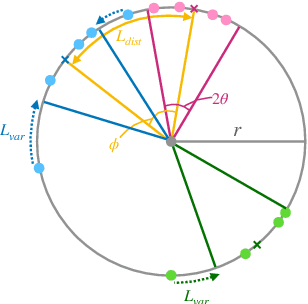
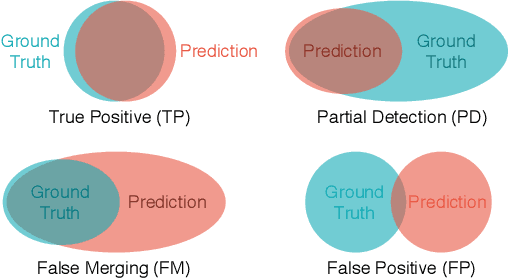
Instance segmentation on 3D point clouds is one of the most extensively researched areas toward the realization of autonomous cars and robots. Certain existing studies have split input point clouds into small regions such as 1m x 1m; one reason for this is that models in the studies cannot consume a large number of points because of the large space complexity. However, because such small regions occasionally include a very small number of instances belonging to the same class, an evaluation using existing metrics such as mAP is largely affected by the category recognition performance. To address these problems, we propose a new method with space complexity O(Np) such that large regions can be consumed, as well as novel metrics for tasks that are independent of the categories or size of the inputs. Our method learns a mapping from input point clouds to an embedding space, where the embeddings form clusters for each instance and distinguish instances using these clusters during testing. Our method achieves state-of-the-art performance using both existing and the proposed metrics. Moreover, we show that our new metric can evaluate the performance of a task without being affected by any other condition.
GRAM: Scalable Generative Models for Graphs with Graph Attention Mechanism
Jun 05, 2019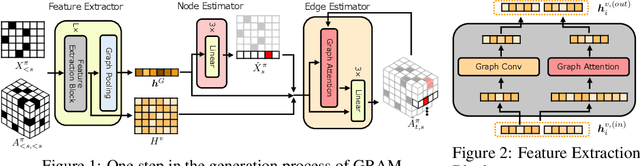
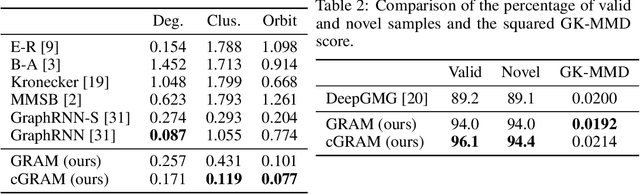
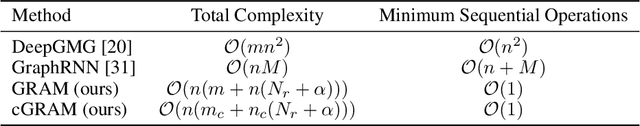
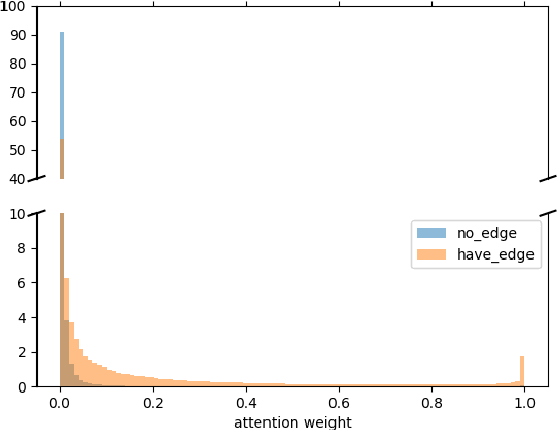
Graphs are ubiquitous real-world data structures, and generative models that can approximate distributions over graphs and derive samples from it have significant importance. There are several known challenges in graph generation tasks, and scalability handling large graphs and datasets is one of the most important for applications in a wide range of real-world domains. Although an increasing number of graph generative models have been proposed in the field of machine learning that have demonstrated impressive results in several tasks, scalability is still an unresolved problem owing to the complex generation process or difficulty in training parallelization. In this work, we first define scalability from three different perspectives: number of nodes, data, and node/edge labels, and then we propose GRAM, a generative model for real-world graphs that is scalable in all the three contexts, especially on training. We aim to achieve scalability by employing a novel graph attention mechanism, formulating the likelihood of graphs in a simple and general manner and utilizing the properties of real-world graphs such as community structure and sparseness of edges. Furthermore, we construct a non-domain-specific evaluation metric in node/edge-labeled graph generation tasks that combine a graph kernel and Maximum Mean Discrepancy. Our experiments on real-world graph datasets showed that our models can scale up to large graphs and datasets that baseline models had difficulty handling, and demonstrated results that were competitive with or superior than the baseline methods.
Invariant Tensor Feature Coding
Jun 05, 2019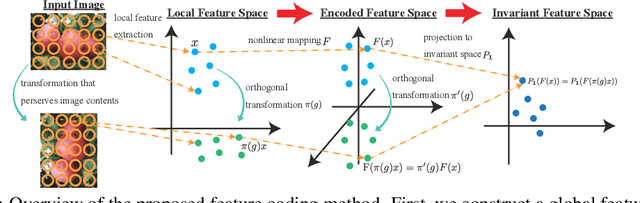
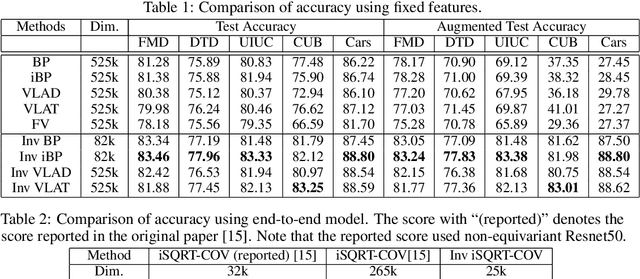
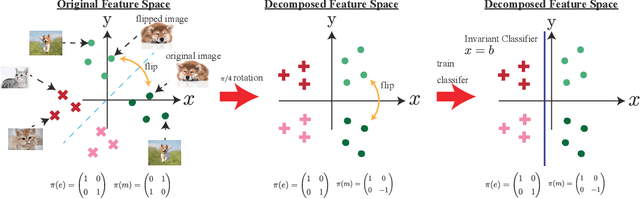
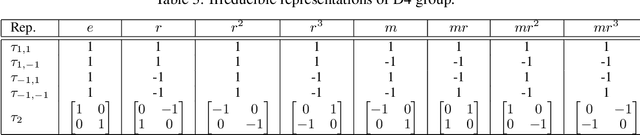
We propose a novel feature coding method that exploits invariance. We consider the setting where the transformations that preserve the image contents compose a finite group of orthogonal matrices. This is the case in many image transformations such as image rotations and image flipping. We prove that the group-invariant feature vector contains sufficient discriminative information when we learn a linear classifier using convex loss minimization. From this result, we propose a novel feature modeling for principal component analysis, and k-means clustering, which are used for most feature coding methods, and global feature functions that explicitly consider the group action. Although the global feature functions are complex nonlinear functions in general, we can calculate the group action on this space easily by constructing the functions as the tensor product representations of basic representations, resulting in the explicit form of invariant feature functions. We demonstrate the effectiveness of our methods on several image datasets.
Compact Approximation for Polynomial of Covariance Feature
Jun 05, 2019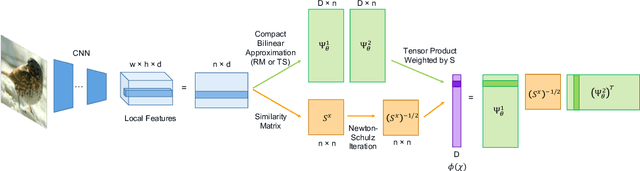

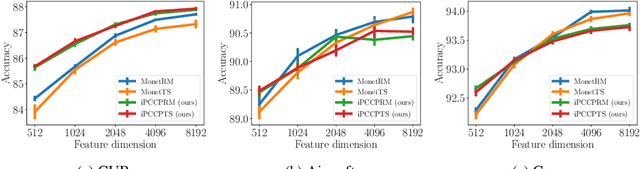
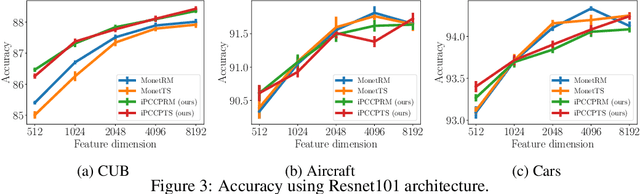
Covariance pooling is a feature pooling method with good classification accuracy. Because covariance features consist of second-order statistics, the scale of the feature elements are varied. Therefore, normalizing covariance features using a matrix square root affects the performance improvement. When pooling methods are applied to local features extracted from CNN models, the accuracy increases when the pooling function is back-propagatable and the feature-extraction model is learned in an end-to-end manner. Recently, the iterative polynomial approximation method for the matrix square root of a covariance feature was proposed, and resulted in a faster and more stable training than the methods based on singular-value decomposition. In this paper, we propose an extension of compact bilinear pooling, which is a compact approximation of the standard covariance feature, to the polynomials of the covariance feature. Subsequently, we apply the proposed approximation to the polynomial corresponding to the matrix square root to obtain a compact approximation for the square root of the covariance feature. Our method approximates a higher-dimensional polynomial of a covariance by the weighted sum of the approximate features corresponding to a pair of local features based on the similarity of the local features. We apply our method for standard fine-grained image recognition datasets and demonstrate that the proposed method shows comparable accuracy with fewer dimensions than the original feature.
Long-Term Video Generation of Multiple Futures Using Human Poses
Apr 17, 2019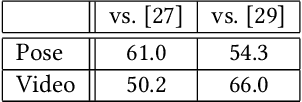
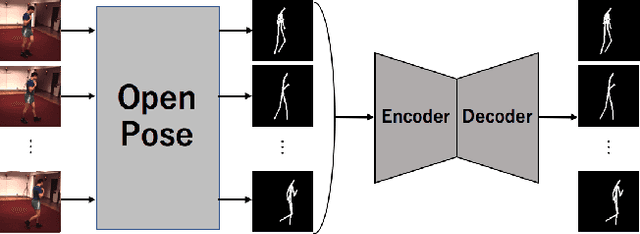
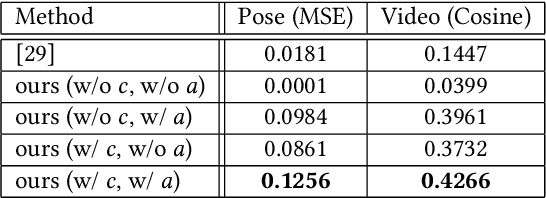
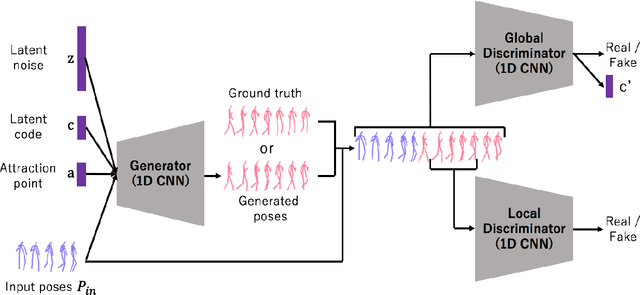
Predicting the near-future from an input video is a useful task for applications such as autonomous driving and robotics. While most previous works predict a single future, multiple futures with different behaviors can possibly occur. Moreover, if the predicted future is too short, it may not be fully usable by a human or other system. In this paper, we propose a novel method for future video prediction capable of generating multiple long-term futures. This makes the predictions more suitable for real applications. First, from an input human video, we generate sequences of future human poses as the image coordinates of their body-joints by adversarial learning. We generate multiple futures by inputting to the generator combinations of a latent code (to reflect various behaviors) and an attraction point (to reflect various trajectories). In addition, we generate long-term future human poses using a novel approach based on unidimensional convolutional neural networks. Last, we generate an output video based on the generated poses for visualization. We evaluate the generated future poses and videos using three criteria (i.e., realism, diversity and accuracy), and show that our proposed method outperforms other state-of-the-art works.
End-to-End Learning Using Cycle Consistency for Image-to-Caption Transformations
Mar 25, 2019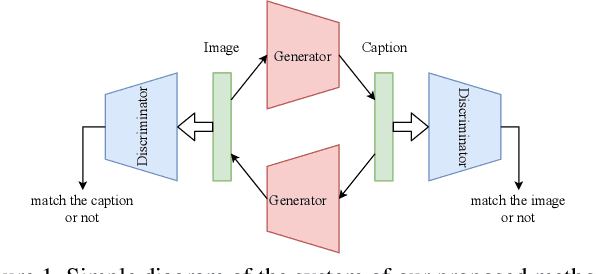
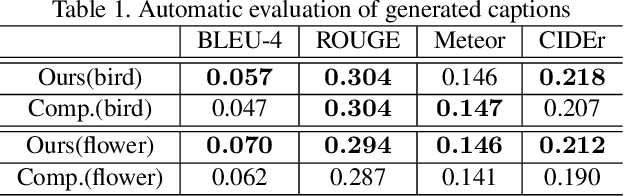
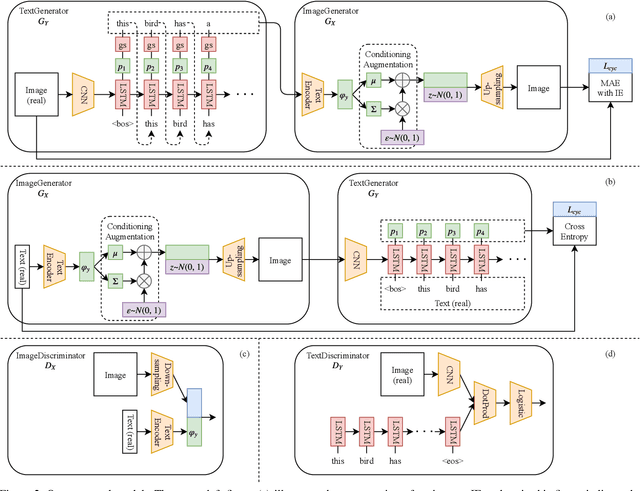
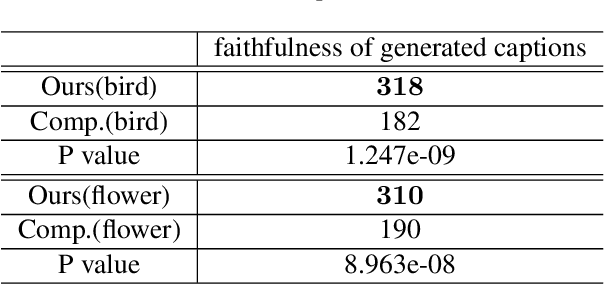
So far, research to generate captions from images has been carried out from the viewpoint that a caption holds sufficient information for an image. If it is possible to generate an image that is close to the input image from a generated caption, i.e., if it is possible to generate a natural language caption containing sufficient information to reproduce the image, then the caption is considered to be faithful to the image. To make such regeneration possible, learning using the cycle-consistency loss is effective. In this study, we propose a method of generating captions by learning end-to-end mutual transformations between images and texts. To evaluate our method, we perform comparative experiments with and without the cycle consistency. The results are evaluated by an automatic evaluation and crowdsourcing, demonstrating that our proposed method is effective.
Weakly supervised collective feature learning from curated media
Feb 13, 2018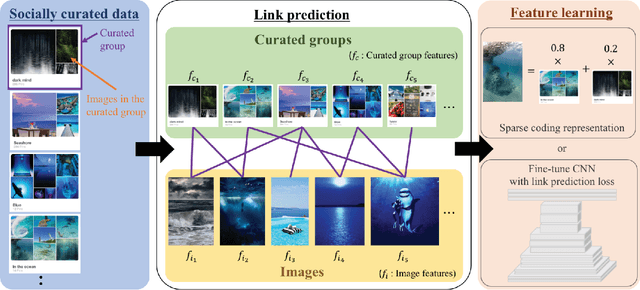
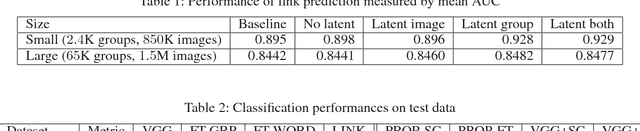
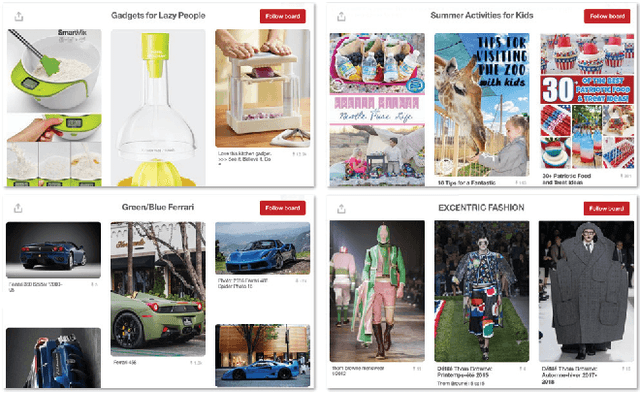

The current state-of-the-art in feature learning relies on the supervised learning of large-scale datasets consisting of target content items and their respective category labels. However, constructing such large-scale fully-labeled datasets generally requires painstaking manual effort. One possible solution to this problem is to employ community contributed text tags as weak labels, however, the concepts underlying a single text tag strongly depends on the users. We instead present a new paradigm for learning discriminative features by making full use of the human curation process on social networking services (SNSs). During the process of content curation, SNS users collect content items manually from various sources and group them by context, all for their own benefit. Due to the nature of this process, we can assume that (1) content items in the same group share the same semantic concept and (2) groups sharing the same images might have related semantic concepts. Through these insights, we can define human curated groups as weak labels from which our proposed framework can learn discriminative features as a representation in the space of semantic concepts the users intended when creating the groups. We show that this feature learning can be formulated as a problem of link prediction for a bipartite graph whose nodes corresponds to content items and human curated groups, and propose a novel method for feature learning based on sparse coding or network fine-tuning.
DeMIAN: Deep Modality Invariant Adversarial Network
Dec 28, 2016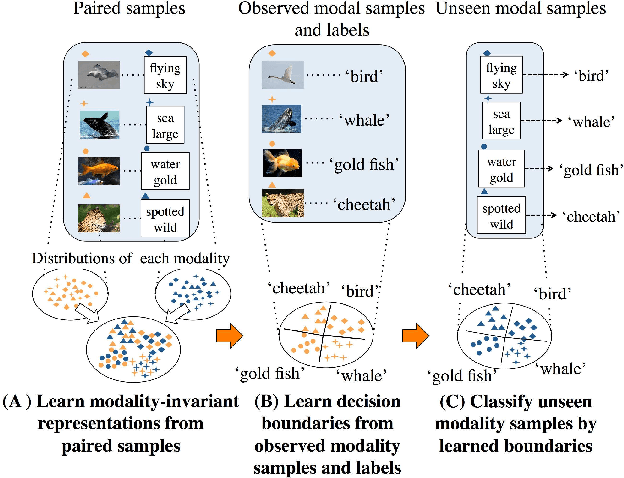
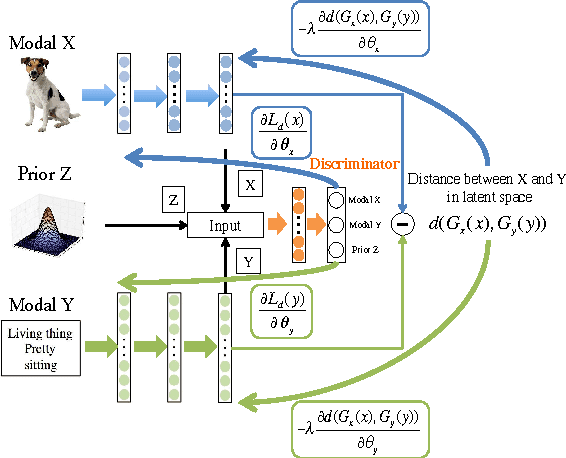
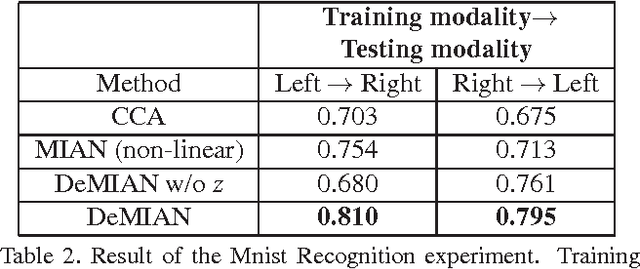
Obtaining common representations from different modalities is important in that they are interchangeable with each other in a classification problem. For example, we can train a classifier on image features in the common representations and apply it to the testing of the text features in the representations. Existing multi-modal representation learning methods mainly aim to extract rich information from paired samples and train a classifier by the corresponding labels; however, collecting paired samples and their labels simultaneously involves high labor costs. Addressing paired modal samples without their labels and single modal data with their labels independently is much easier than addressing labeled multi-modal data. To obtain the common representations under such a situation, we propose to make the distributions over different modalities similar in the learned representations, namely modality-invariant representations. In particular, we propose a novel algorithm for modality-invariant representation learning, named Deep Modality Invariant Adversarial Network (DeMIAN), which utilizes the idea of Domain Adaptation (DA). Using the modality-invariant representations learned by DeMIAN, we achieved better classification accuracy than with the state-of-the-art methods, especially for some benchmark datasets of zero-shot learning.