 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Reason Well, Until They Don't
Oct 25, 2025Large language models (LLMs) have shown significant progress in reasoning tasks. However, recent studies show that transformers and LLMs fail catastrophically once reasoning problems exceed modest complexity. We revisit these findings through the lens of large reasoning models (LRMs) -- LLMs fine-tuned with incentives for step-by-step argumentation and self-verification. LRM performance on graph and reasoning benchmarks such as NLGraph seem extraordinary, with some even claiming they are capable of generalized reasoning and innovation in reasoning-intensive fields such as mathematics, physics, medicine, and law. However, by more carefully scaling the complexity of reasoning problems, we show existing benchmarks actually have limited complexity. We develop a new dataset, the Deep Reasoning Dataset (DeepRD), along with a generative process for producing unlimited examples of scalable complexity. We use this dataset to evaluate model performance on graph connectivity and natural language proof planning. We find that the performance of LRMs drop abruptly at sufficient complexity and do not generalize. We also relate our LRM results to the distributions of the complexities of large, real-world knowledge graphs, interaction graphs, and proof datasets. We find the majority of real-world examples fall inside the LRMs' success regime, yet the long tails expose substantial failure potential. Our analysis highlights the near-term utility of LRMs while underscoring the need for new methods that generalize beyond the complexity of examples in the training distribution.
Language Models Do Not Follow Occam's Razor: A Benchmark for Inductive and Abductive Reasoning
Sep 03, 2025Reasoning is a core capability in artificial intelligence systems, for which large language models (LLMs) have recently shown remarkable progress. However, most work focuses exclusively on deductive reasoning, which is problematic since other types of reasoning are also essential in solving real-world problems, and they are less explored. This work focuses on evaluating LLMs' inductive and abductive reasoning capabilities. We introduce a programmable and synthetic dataset, InAbHyD (pronounced in-a-bid), where each reasoning example consists of an incomplete world model and a set of observations. The task for the intelligent agent is to produce hypotheses to explain observations under the incomplete world model to solve each reasoning example. We propose a new metric to evaluate the quality of hypotheses based on Occam's Razor. We evaluate and analyze some state-of-the-art LLMs. Our analysis shows that LLMs can perform inductive and abductive reasoning in simple scenarios, but struggle with complex world models and producing high-quality hypotheses, even with popular reasoning-enhancing techniques such as in-context learning and RLVR.
Semantic Softmax Loss for Zero-Shot Learning
May 22, 2017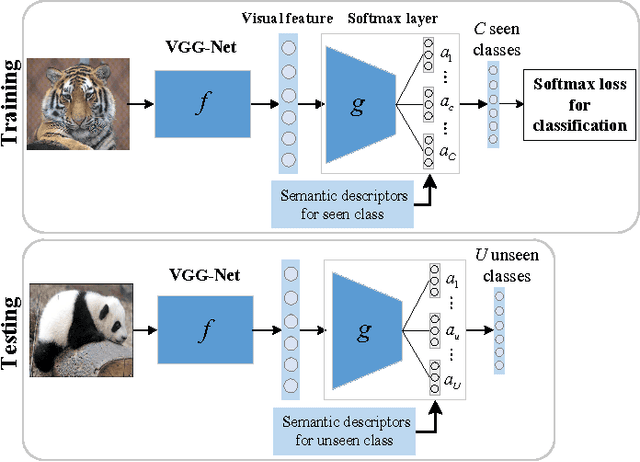
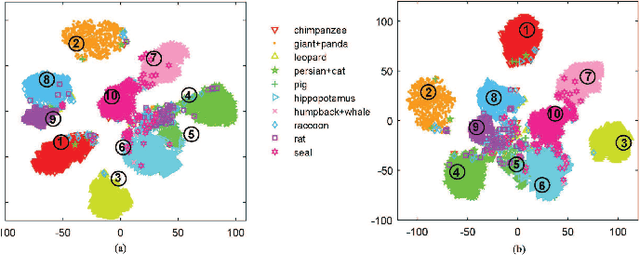
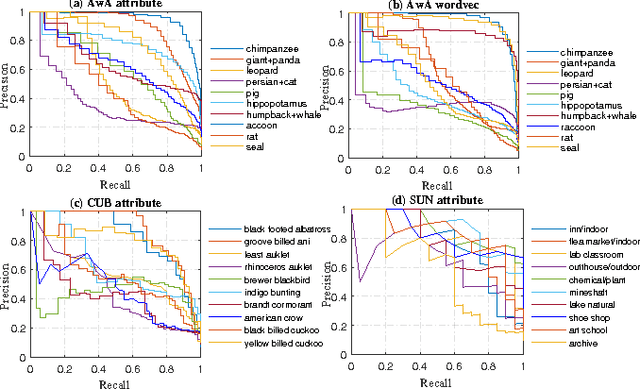
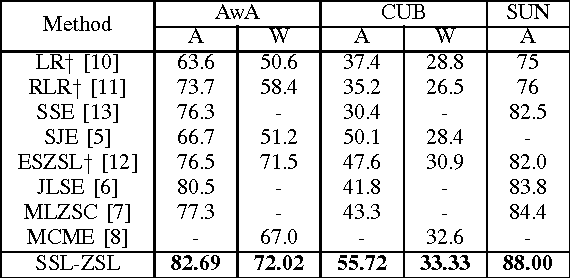
A typical pipeline for Zero-Shot Learning (ZSL) is to integrate the visual features and the class semantic descriptors into a multimodal framework with a linear or bilinear model. However, the visual features and the class semantic descriptors locate in different structural spaces, a linear or bilinear model can not capture the semantic interactions between different modalities well. In this letter, we propose a nonlinear approach to impose ZSL as a multi-class classification problem via a Semantic Softmax Loss by embedding the class semantic descriptors into the softmax layer of multi-class classification network. To narrow the structural differences between the visual features and semantic descriptors, we further use an L2 normalization constraint to the differences between the visual features and visual prototypes reconstructed with the semantic descriptors. The results on three benchmark datasets, i.e., AwA, CUB and SUN demonstrate the proposed approach can boost the performances steadily and achieve the state-of-the-art performance for both zero-shot classification and zero-shot retrieval.