 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Grounded Multimodal Benchmark with 900K-Scale Aggregated Student Response Distributions from Japan's National Assessment of Academic Ability
May 12, 2026Authentic school examinations provide a high-validity test bed for evaluating multimodal large language models (MLLMs), yet benchmarks grounded in Japanese K-12 assessments remain scarce. We present a multimodal dataset constructed from Japan's National Assessment of Academic Ability, comprising officially released middle-school items in Science, Mathematics, and Japanese Language. Unlike existing benchmarks based on synthetic or curated data, our dataset preserves real exam layouts, diagrams, and Japanese educational text, together with nationwide aggregated student response distributions (N $\approx$ 900{,}000). These features enable direct comparison between human and model performance under a unified evaluation framework. We benchmark recent multimodal LLMs using exact-match accuracy and character-level F1 for open-ended responses, observing substantial variation across subjects and strong sensitivity to visual reasoning demands. Human evaluation and LLM-as-judge analyses further assess the reliability of automatic scoring. Our dataset establishes a reproducible, human-grounded benchmark for multimodal educational reasoning and supports future research on evaluation, feedback generation, and explainable AI in authentic assessment contexts. Our dataset is available at: https://github.com/KyosukeTakami/gakucho-benchmark
A Quantitative Evaluation of Natural Language Question Interpretation for Question Answering Systems
Sep 20, 2018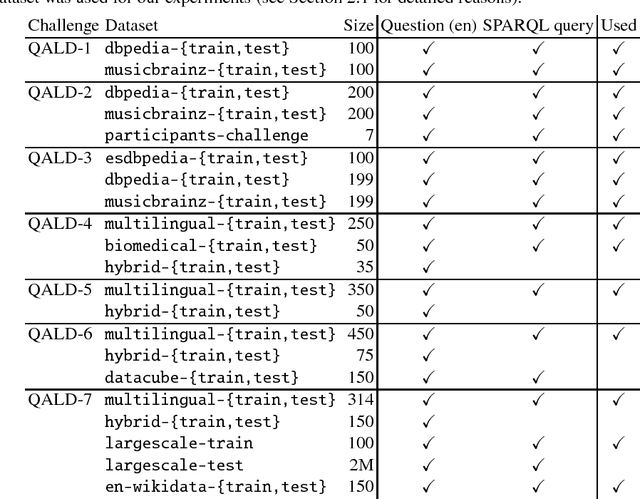
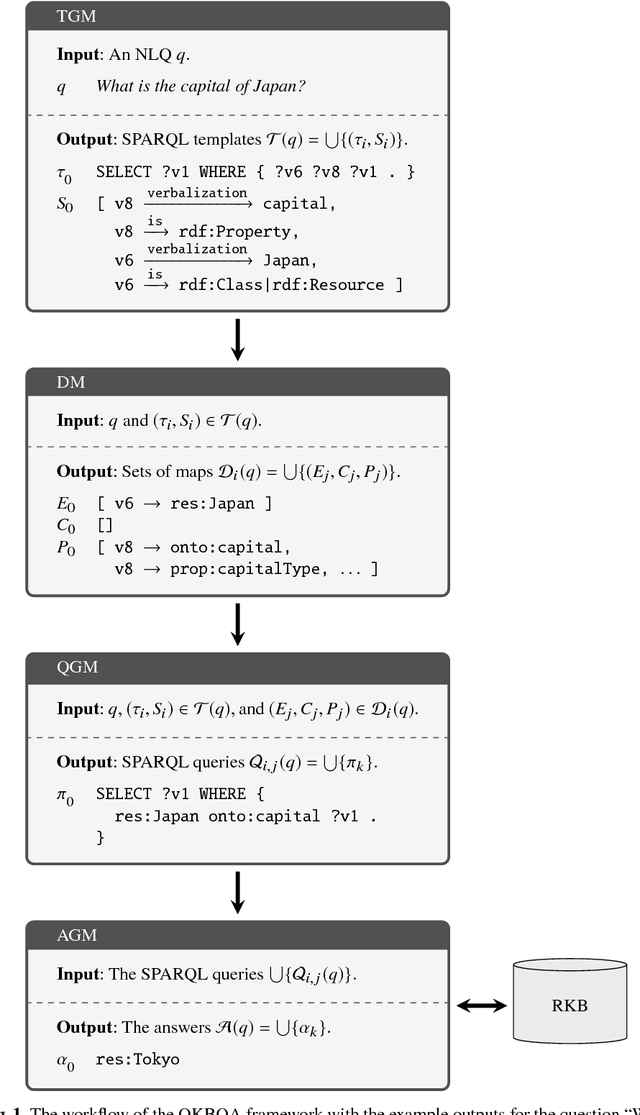
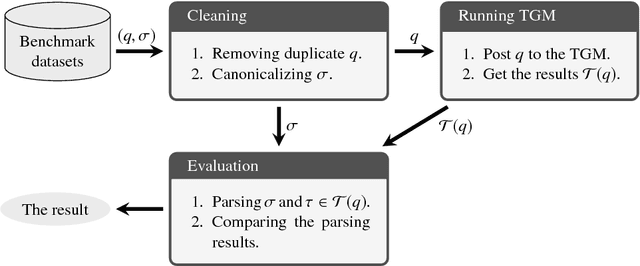

Systematic benchmark evaluation plays an important role in the process of improving technologies for Question Answering (QA) systems. While currently there are a number of existing evaluation methods for natural language (NL) QA systems, most of them consider only the final answers, limiting their utility within a black box style evaluation. Herein, we propose a subdivided evaluation approach to enable finer-grained evaluation of QA systems, and present an evaluation tool which targets the NL question (NLQ) interpretation step, an initial step of a QA pipeline. The results of experiments using two public benchmark datasets suggest that we can get a deeper insight about the performance of a QA system using the proposed approach, which should provide a better guidance for improving the systems, than using black box style approaches.