 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Lexical Substitution with Decontextualised Embeddings
Sep 17, 2022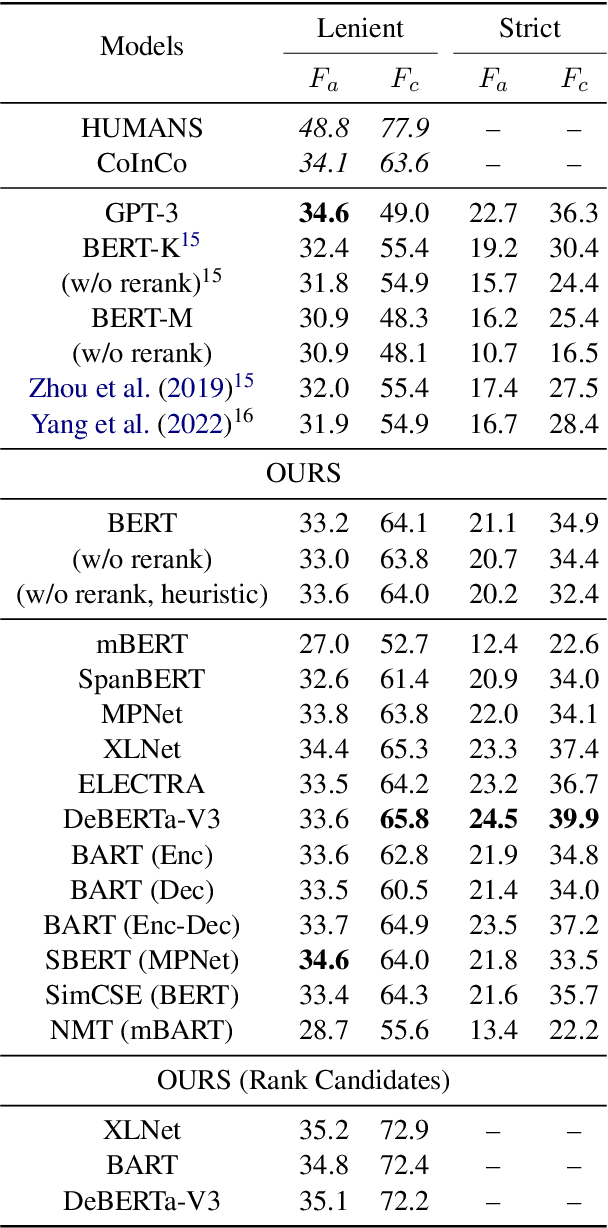
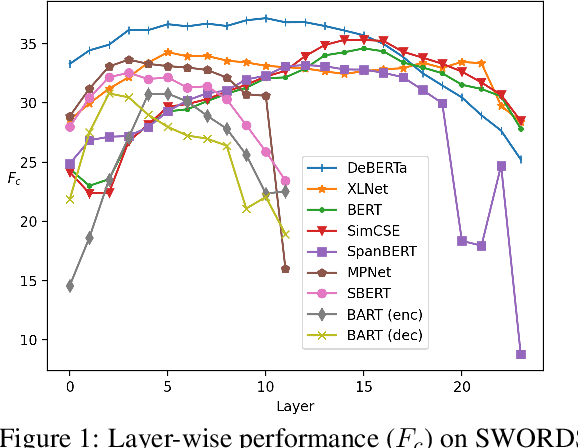
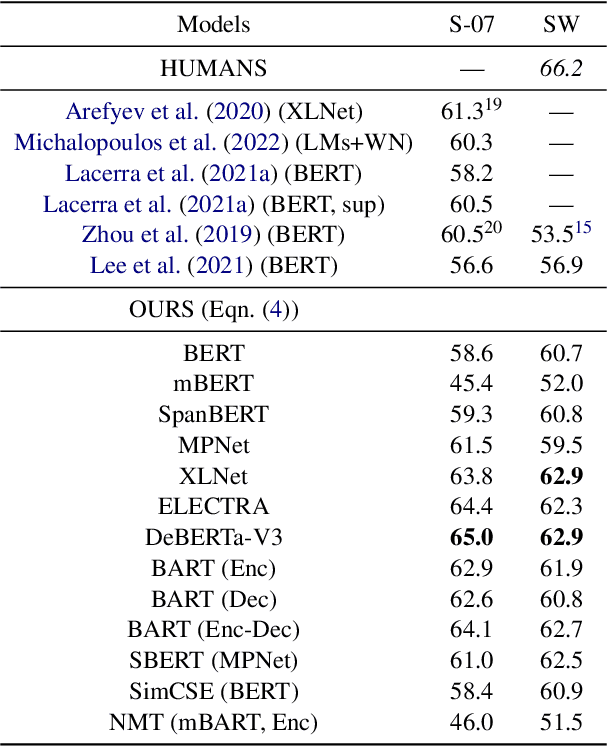
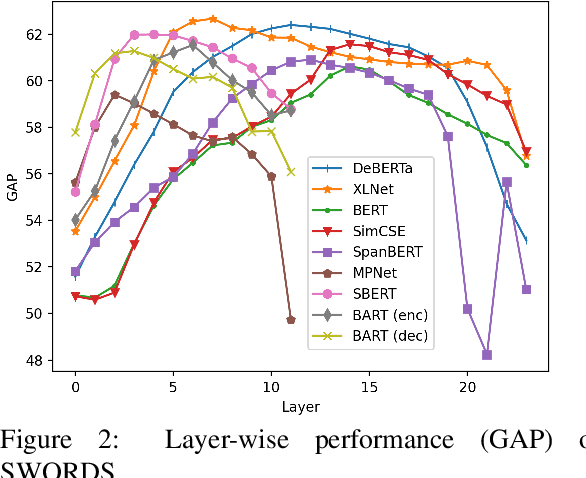
We propose a new unsupervised method for lexical substitution using pre-trained language models. Compared to previous approaches that use the generative capability of language models to predict substitutes, our method retrieves substitutes based on the similarity of contextualised and decontextualised word embeddings, i.e. the average contextual representation of a word in multiple contexts. We conduct experiments in English and Italian, and show that our method substantially outperforms strong baselines and establishes a new state-of-the-art without any explicit supervision or fine-tuning. We further show that our method performs particularly well at predicting low-frequency substitutes, and also generates a diverse list of substitute candidates, reducing morphophonetic or morphosyntactic biases induced by article-noun agreement.
Removing Word-Level Spurious Alignment between Images and Pseudo-Captions in Unsupervised Image Captioning
Apr 28, 2021


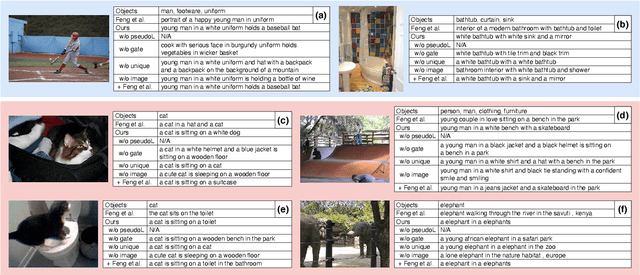
Unsupervised image captioning is a challenging task that aims at generating captions without the supervision of image-sentence pairs, but only with images and sentences drawn from different sources and object labels detected from the images. In previous work, pseudo-captions, i.e., sentences that contain the detected object labels, were assigned to a given image. The focus of the previous work was on the alignment of input images and pseudo-captions at the sentence level. However, pseudo-captions contain many words that are irrelevant to a given image. In this work, we investigate the effect of removing mismatched words from image-sentence alignment to determine how they make this task difficult. We propose a simple gating mechanism that is trained to align image features with only the most reliable words in pseudo-captions: the detected object labels. The experimental results show that our proposed method outperforms the previous methods without introducing complex sentence-level learning objectives. Combined with the sentence-level alignment method of previous work, our method further improves its performance. These results confirm the importance of careful alignment in word-level details.
Learning Contextualised Cross-lingual Word Embeddings for Extremely Low-Resource Languages Using Parallel Corpora
Oct 27, 2020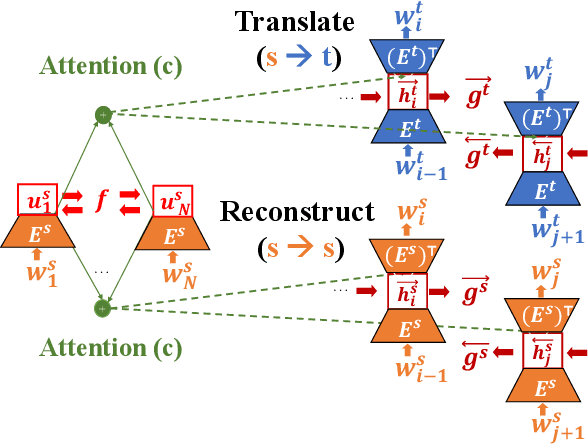
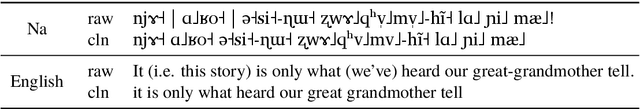
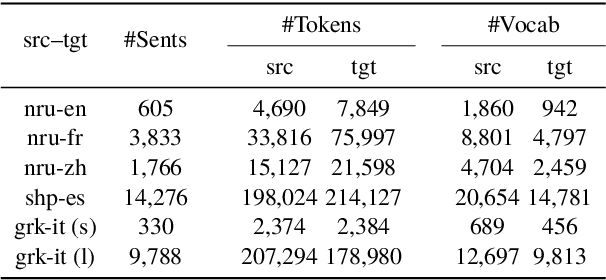
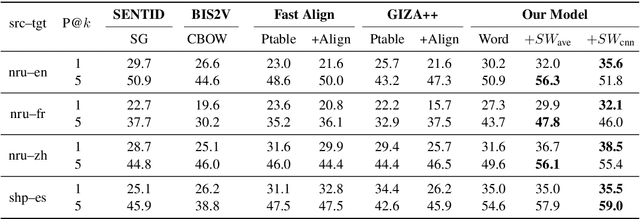
We propose a new approach for learning contextualised cross-lingual word embeddings based only on a small parallel corpus (e.g. a few hundred sentence pairs). Our method obtains word embeddings via an LSTM-based encoder-decoder model that performs bidirectional translation and reconstruction of the input sentence. Through sharing model parameters among different languages, our model jointly trains the word embeddings in a common multilingual space. We also propose a simple method to combine word and subword embeddings to make use of orthographic similarities across different languages. We base our experiments on real-world data from endangered languages, namely Yongning Na, Shipibo-Konibo and Griko. Our experiments on bilingual lexicon induction and word alignment tasks show that our model outperforms existing methods by a large margin for most language pairs. These results demonstrate that, contrary to common belief, an encoder-decoder translation model is beneficial for learning cross-lingual representations, even in extremely low-resource scenarios.
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Oct 02, 2020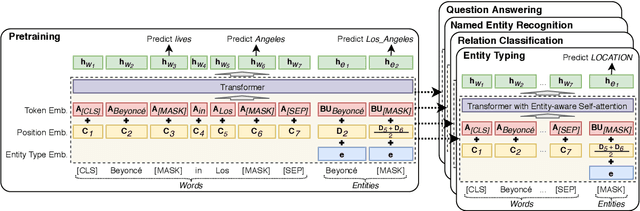
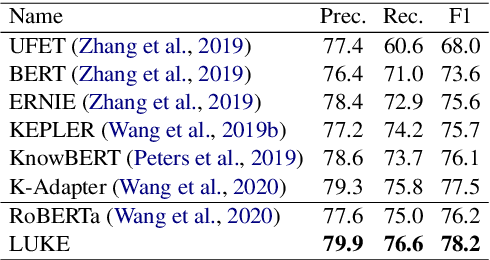
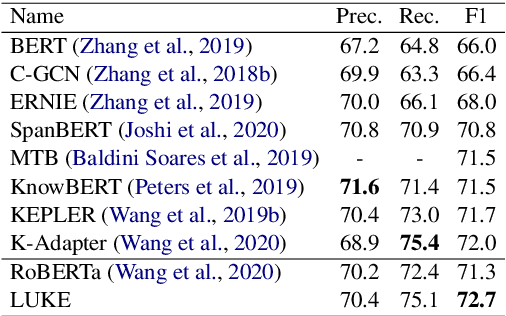
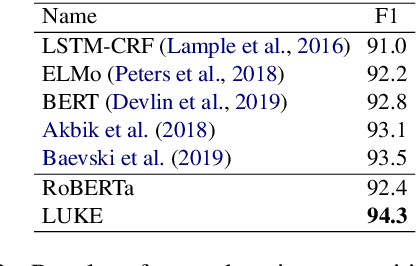
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entities in a given text as independent tokens, and outputs contextualized representations of them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification), CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question answering). Our source code and pretrained representations are available at https://github.com/studio-ousia/luke.
Length-controllable Abstractive Summarization by Guiding with Summary Prototype
Jan 21, 2020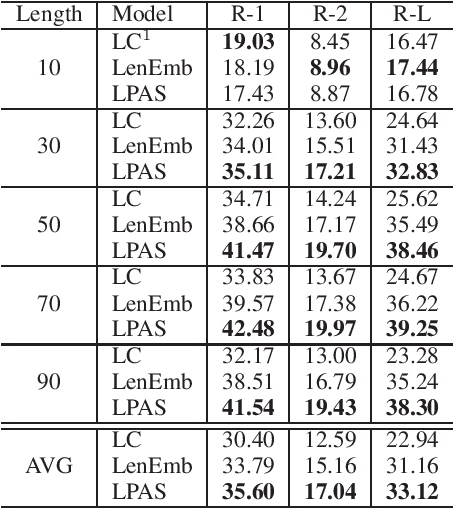
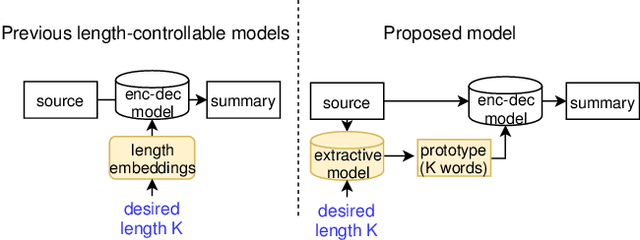
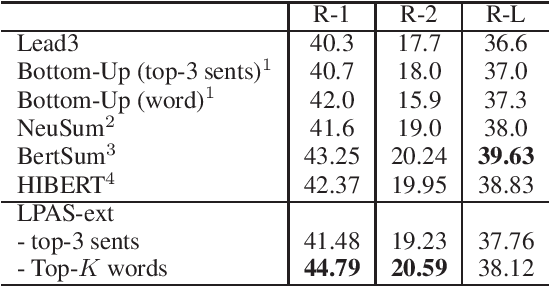
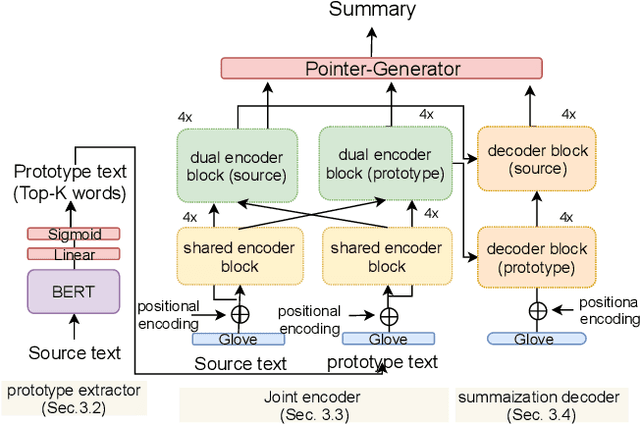
We propose a new length-controllable abstractive summarization model. Recent state-of-the-art abstractive summarization models based on encoder-decoder models generate only one summary per source text. However, controllable summarization, especially of the length, is an important aspect for practical applications. Previous studies on length-controllable abstractive summarization incorporate length embeddings in the decoder module for controlling the summary length. Although the length embeddings can control where to stop decoding, they do not decide which information should be included in the summary within the length constraint. Unlike the previous models, our length-controllable abstractive summarization model incorporates a word-level extractive module in the encoder-decoder model instead of length embeddings. Our model generates a summary in two steps. First, our word-level extractor extracts a sequence of important words (we call it the "prototype text") from the source text according to the word-level importance scores and the length constraint. Second, the prototype text is used as additional input to the encoder-decoder model, which generates a summary by jointly encoding and copying words from both the prototype text and source text. Since the prototype text is a guide to both the content and length of the summary, our model can generate an informative and length-controlled summary. Experiments with the CNN/Daily Mail dataset and the NEWSROOM dataset show that our model outperformed previous models in length-controlled settings.
Gated Graph Recursive Neural Networks for Molecular Property Prediction
Aug 31, 2019
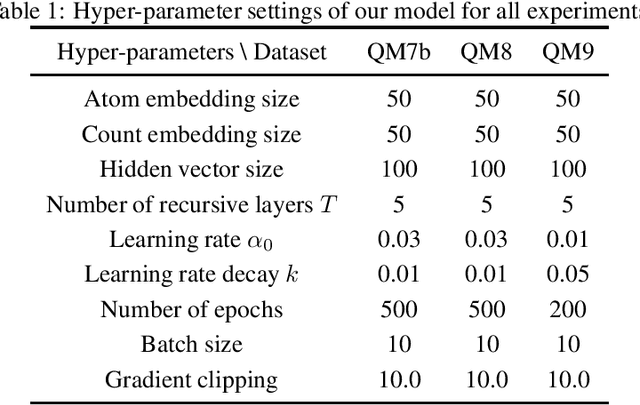
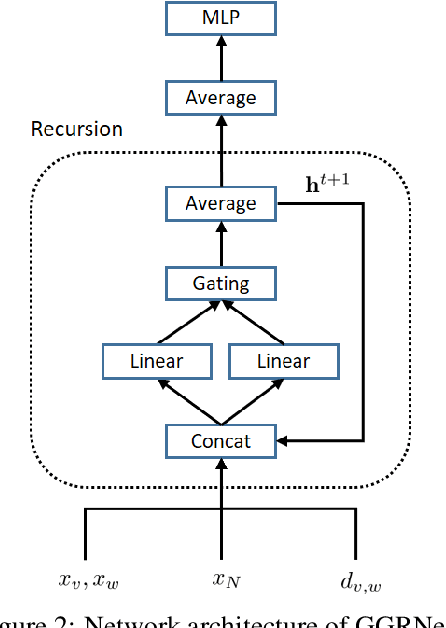
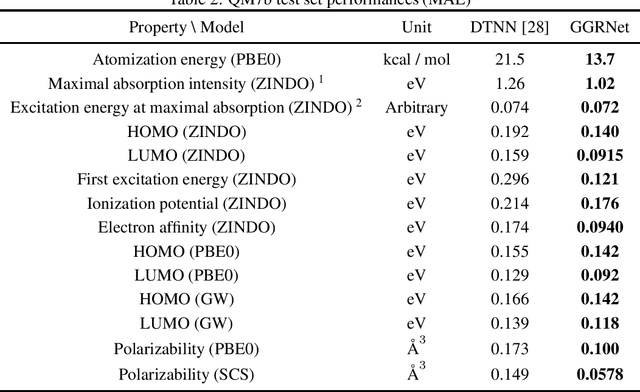
Molecule property prediction is a fundamental problem for computer-aided drug discovery and materials science. Quantum-chemical simulations such as density functional theory (DFT) have been widely used for calculating the molecule properties, however, because of the heavy computational cost, it is difficult to search a huge number of potential chemical compounds. Machine learning methods for molecular modeling are attractive alternatives, however, the development of expressive, accurate, and scalable graph neural networks for learning molecular representations is still challenging. In this work, we propose a simple and powerful graph neural networks for molecular property prediction. We model a molecular as a directed complete graph in which each atom has a spatial position, and introduce a recursive neural network with simple gating function. We also feed input embeddings for every layers as skip connections to accelerate the training. Experimental results show that our model achieves the state-of-the-art performance on the standard benchmark dataset for molecular property prediction.
Improving Multi-Word Entity Recognition for Biomedical Texts
Aug 15, 2019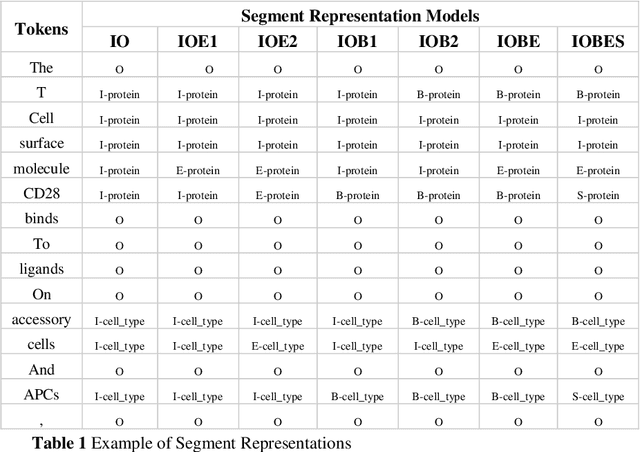
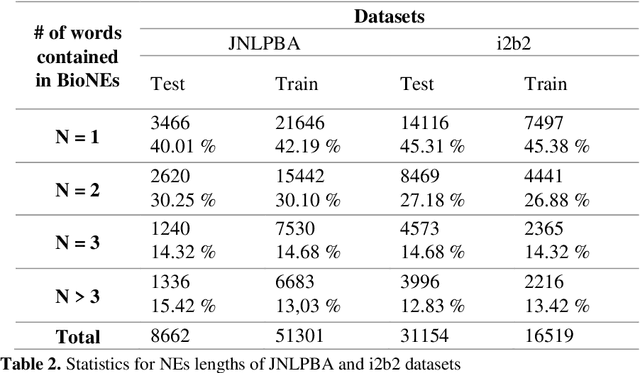
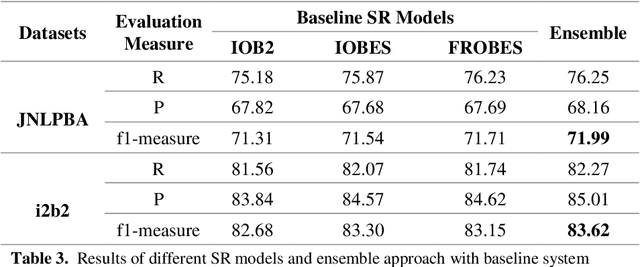
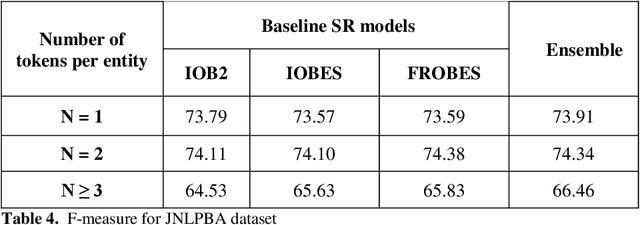
Biomedical Named Entity Recognition (BioNER) is a crucial step for analyzing Biomedical texts, which aims at extracting biomedical named entities from a given text. Different supervised machine learning algorithms have been applied for BioNER by various researchers. The main requirement of these approaches is an annotated dataset used for learning the parameters of machine learning algorithms. Segment Representation (SR) models comprise of different tag sets used for representing the annotated data, such as IOB2, IOE2 and IOBES. In this paper, we propose an extension of IOBES model to improve the performance of BioNER. The proposed SR model, FROBES, improves the representation of multi-word entities. We used Bidirectional Long Short-Term Memory (BiLSTM) network; an instance of Recurrent Neural Networks (RNN), to design a baseline system for BioNER and evaluated the new SR model on two datasets, i2b2/VA 2010 challenge dataset and JNLPBA 2004 shared task dataset. The proposed SR model outperforms other models for multi-word entities with length greater than two. Further, the outputs of different SR models have been combined using majority voting ensemble method which outperforms the baseline models performance.
* 13 pages, 2 figures, International Conference on Cognitive Informatics and Soft Computing (ICCISC-2017)
Playing by the Book: Towards Agent-based Narrative Understanding through Role-playing and Simulation
Nov 10, 2018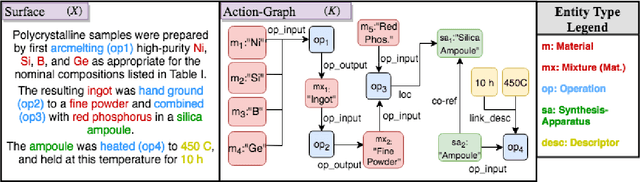

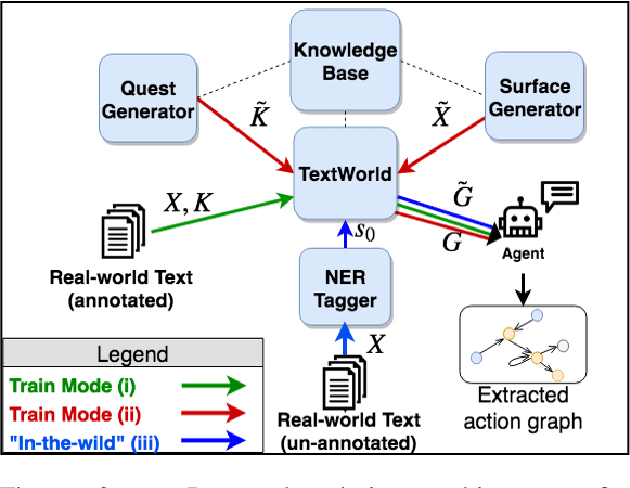
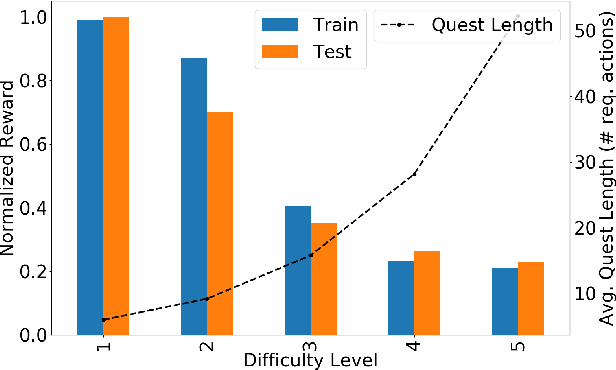
Understanding procedural text requires tracking entities, actions and effects as the narrative unfolds (often implicitly). We focus on the challenging real-world problem of structured narrative extraction in the materials science domain, where language is highly specialized and suitable annotated data is not publicly available. We propose an approach, Text2Quest, where procedural text is interpreted as instructions for an interactive game. A reinforcement-learning agent completes the game by understanding and executing the procedure correctly, in a text-based simulated lab environment. The framework is intended to be more broadly applicable to other domain-specific and data-scarce settings. We conclude with a discussion of challenges and interesting potential extensions enabled by the agent-based perspective.
Reduction of Parameter Redundancy in Biaffine Classifiers with Symmetric and Circulant Weight Matrices
Oct 18, 2018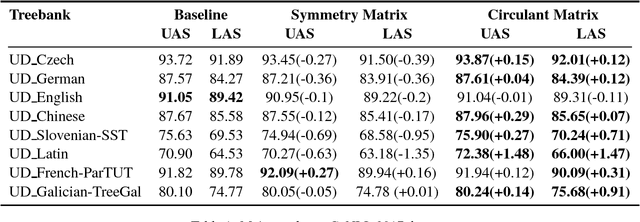
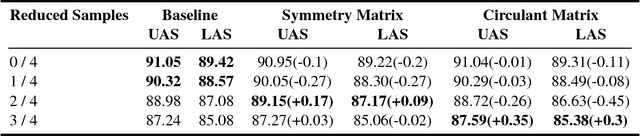
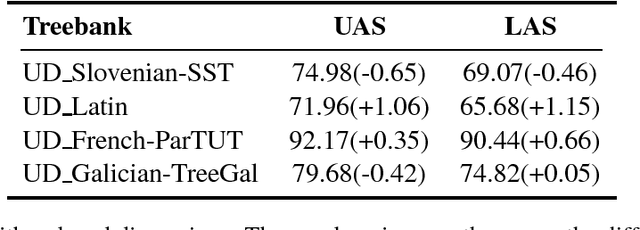
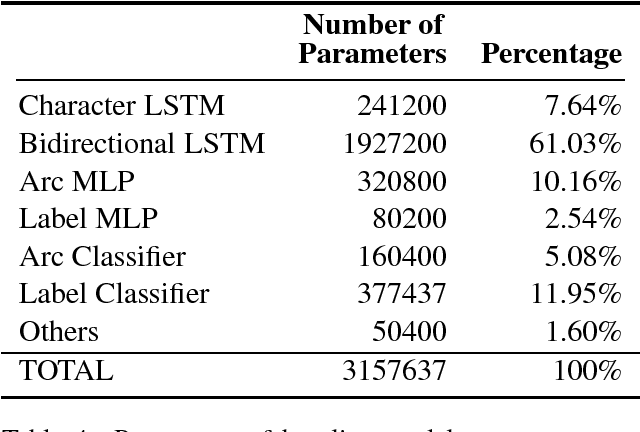
Currently, the biaffine classifier has been attracting attention as a method to introduce an attention mechanism into the modeling of binary relations. For instance, in the field of dependency parsing, the Deep Biaffine Parser by Dozat and Manning has achieved state-of-the-art performance as a graph-based dependency parser on the English Penn Treebank and CoNLL 2017 shared task. On the other hand, it is reported that parameter redundancy in the weight matrix in biaffine classifiers, which has O(n^2) parameters, results in overfitting (n is the number of dimensions). In this paper, we attempted to reduce the parameter redundancy by assuming either symmetry or circularity of weight matrices. In our experiments on the CoNLL 2017 shared task dataset, our model achieved better or comparable accuracy on most of the treebanks with more than 16% parameter reduction.
A Fast and Easy Regression Technique for k-NN Classification Without Using Negative Pairs
Jun 11, 2018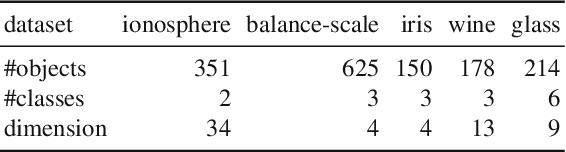
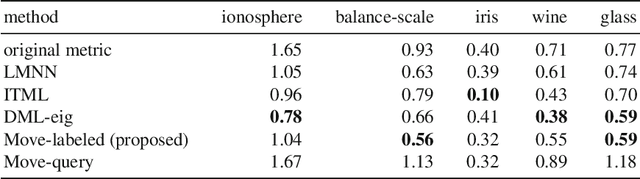
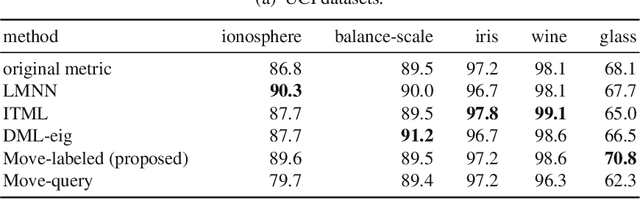
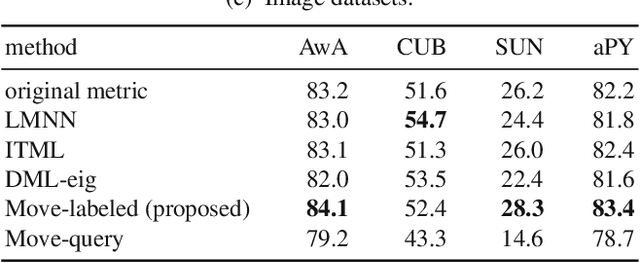
This paper proposes an inexpensive way to learn an effective dissimilarity function to be used for $k$-nearest neighbor ($k$-NN) classification. Unlike Mahalanobis metric learning methods that map both query (unlabeled) objects and labeled objects to new coordinates by a single transformation, our method learns a transformation of labeled objects to new points in the feature space whereas query objects are kept in their original coordinates. This method has several advantages over existing distance metric learning methods: (i) In experiments with large document and image datasets, it achieves $k$-NN classification accuracy better than or at least comparable to the state-of-the-art metric learning methods. (ii) The transformation can be learned efficiently by solving a standard ridge regression problem. For document and image datasets, training is often more than two orders of magnitude faster than the fastest metric learning methods tested. This speed-up is also due to the fact that the proposed method eliminates the optimization over "negative" object pairs, i.e., objects whose class labels are different. (iii) The formulation has a theoretical justification in terms of reducing hubness in data.