 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA Implementations of 3D-SIMD Processor Architecture for Deep Neural Networks Using Relative Indexed Compressed Sparse Filter Encoding Format and Stacked Filters Stationary Flow
Apr 12, 2018


It is a challenging task to deploy computationally and memory intensive State-of-the-art deep neural networks (DNNs) on embedded systems with limited hardware resources and power budgets. Recently developed techniques like Deep Compression make it possible to fit large DNNs, such as AlexNet and VGGNet, fully in on-chip SRAM. But sparse networks compressed using existing encoding formats, like CSR or CSC, complex the computation at runtime due to their irregular memory access characteristics. In [1], we introduce a computation dataflow, stacked filters stationary dataflow (SFS), and a corresponding data encoding format, relative indexed compressed sparse filter format (CSF), to make the best of data sparsity, and simplify data handling at execution time. In this paper we present FPGA implementations of these methods. We implement several compact streaming fully connected (FC) and Convolutional (CONV) neural network processors to show their efficiency. Comparing with the state-of-the-art results [2,3,4], our methods achieve at least 2x improvement for computation efficiency per PE on most layers. Especially, our methods achieve 8x improvement on AlexNet layer CONV4 with 384 filters, and 11x improvement on VGG16 layer CONV5-3 with 512 filters.
Stacked Filters Stationary Flow For Hardware-Oriented Acceleration Of Deep Convolutional Neural Networks
Feb 06, 2018
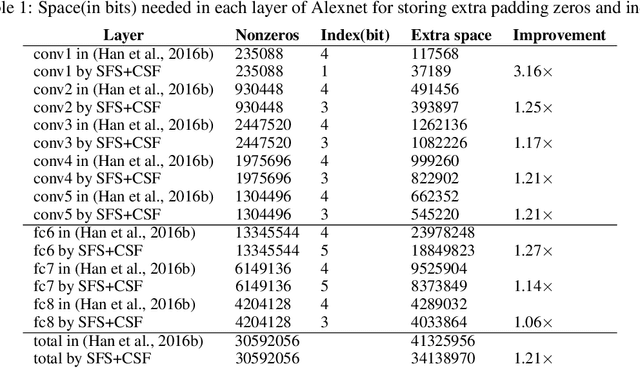


To address memory and computation resource limitations for hardware-oriented acceleration of deep convolutional neural networks (CNNs), we present a computation flow, stacked filters stationary flow (SFS), and a corresponding data encoding format, relative indexed compressed sparse filter format (CSF), to make the best of data sparsity, and simplify data handling at execution time. And we also propose a three dimensional Single Instruction Multiple Data (3D-SIMD) processor architecture to illustrate how to accelerate deep CNNs by taking advantage of SFS flow and CSF format. Comparing with the state-of-the-art result (Han et al., 2016b), our methods achieve 1.11x improvement in reducing the storage required by AlexNet, and 1.09x improvement in reducing the storage required by SqueezeNet, without loss of accuracy on the ImageNet dataset. Moreover, using these approaches, chip area for logics handling irregular sparse data access can be saved. Comparing with the 2D-SIMD processor structures in DVAS, ENVISION, etc., our methods achieve about 3.65x processing element (PE) array utilization rate improvement (from 26.4\% to 96.5\%) on the data from Deep Compression on AlexNet.