 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
Paper and Code



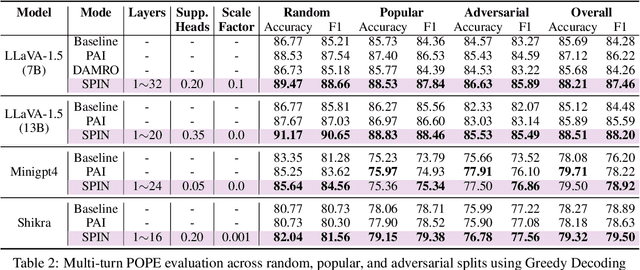
Despite their remarkable progress in multimodal understanding tasks, large vision language models (LVLMs) often suffer from "hallucinations", generating texts misaligned with the visual context. Existing methods aimed at reducing hallucinations through inference time intervention incur a significant increase in latency. To mitigate this, we present SPIN, a task-agnostic attention-guided head suppression strategy that can be seamlessly integrated during inference, without incurring any significant compute or latency overhead. We investigate whether hallucination in LVLMs can be linked to specific model components. Our analysis suggests that hallucinations can be attributed to a dynamic subset of attention heads in each layer. Leveraging this insight, for each text query token, we selectively suppress attention heads that exhibit low attention to image tokens, keeping the top-K attention heads intact. Extensive evaluations on visual question answering and image description tasks demonstrate the efficacy of SPIN in reducing hallucination scores up to 2.7x while maintaining F1, and improving throughput by 1.8x compared to existing alternatives. Code is available at https://github.com/YUECHE77/SPIN.