 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation Quality Score for Measuring the Quality of interpretability methods
May 24, 2022
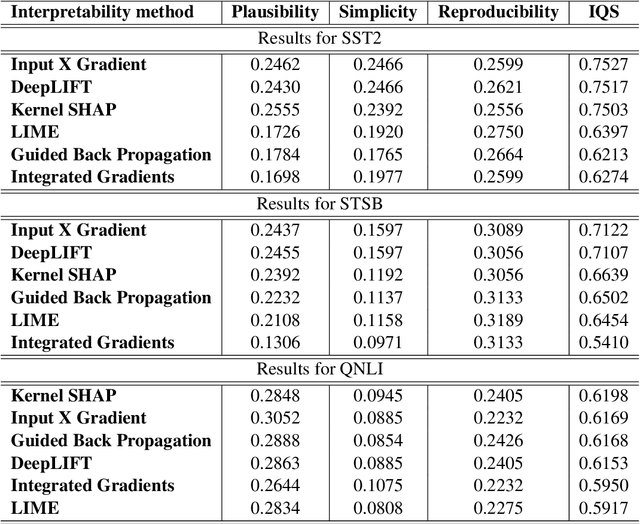

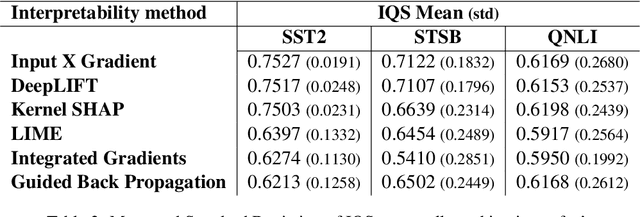
Machine learning (ML) models have been applied to a wide range of natural language processing (NLP) tasks in recent years. In addition to making accurate decisions, the necessity of understanding how models make their decisions has become apparent in many applications. To that end, many interpretability methods that help explain the decision processes of ML models have been developed. Yet, there currently exists no widely-accepted metric to evaluate the quality of explanations generated by these methods. As a result, there currently is no standard way of measuring to what degree an interpretability method achieves an intended objective. Moreover, there is no accepted standard of performance by which we can compare and rank the current existing interpretability methods. In this paper, we propose a novel metric for quantifying the quality of explanations generated by interpretability methods. We compute the metric on three NLP tasks using six interpretability methods and present our results.
Towards Interpretable Deep Reinforcement Learning Models via Inverse Reinforcement Learning
Mar 30, 2022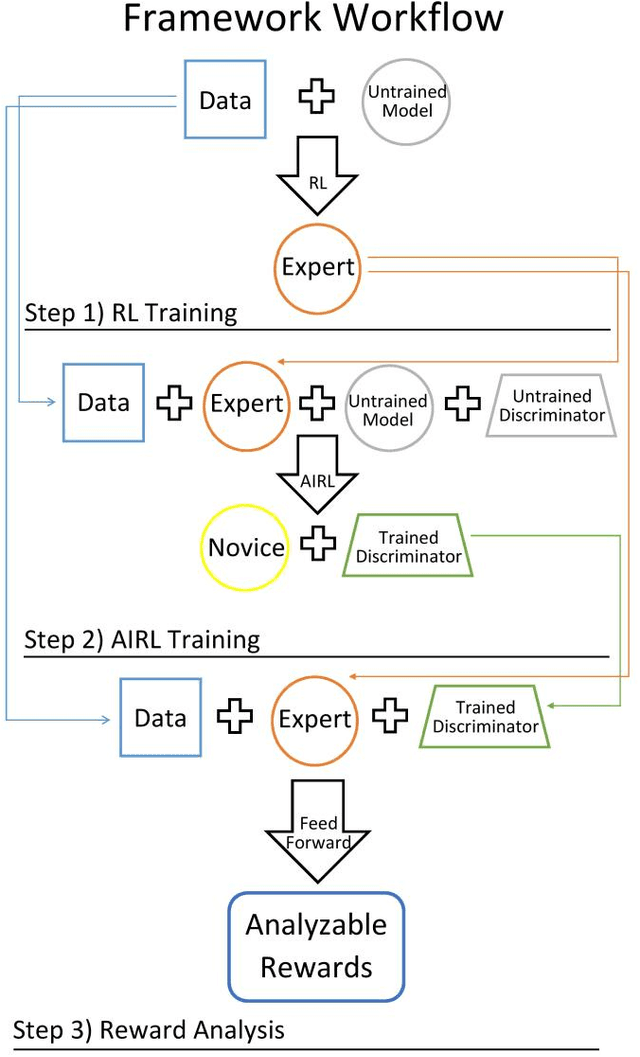
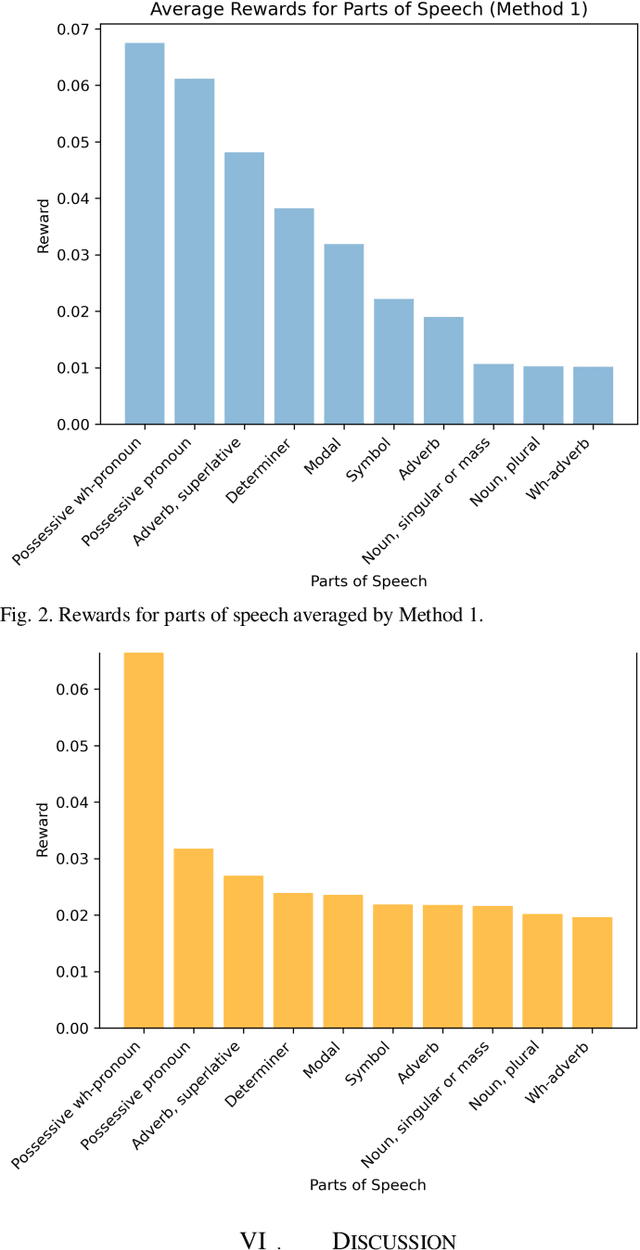

Artificial intelligence, particularly through recent advancements in deep learning, has achieved exceptional performances in many tasks in fields such as natural language processing and computer vision. In addition to desirable evaluation metrics, a high level of interpretability is often required for these models to be reliably utilized. Therefore, explanations that offer insight into the process by which a model maps its inputs onto its outputs are much sought-after. Unfortunately, current black box nature of machine learning models is still an unresolved issue and this very nature prevents researchers from learning and providing explicative descriptions for a model's behavior and final predictions. In this work, we propose a novel framework utilizing Adversarial Inverse Reinforcement Learning that can provide global explanations for decisions made by a Reinforcement Learning model and capture intuitive tendencies that the model follows by summarizing the model's decision-making process.